GPT evaluation, Great Expectations, real-time streaming, TypeScript support, and new docs
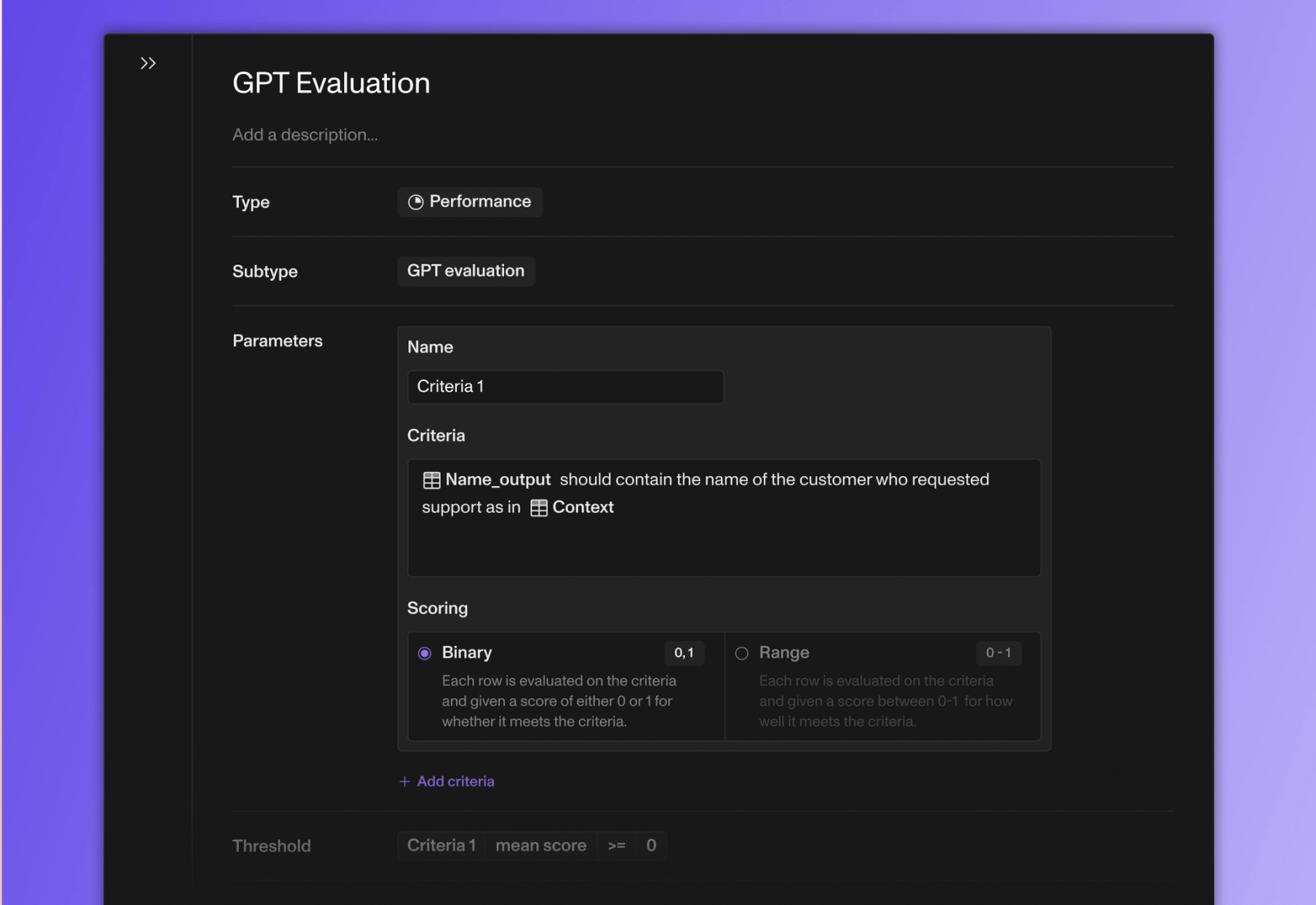
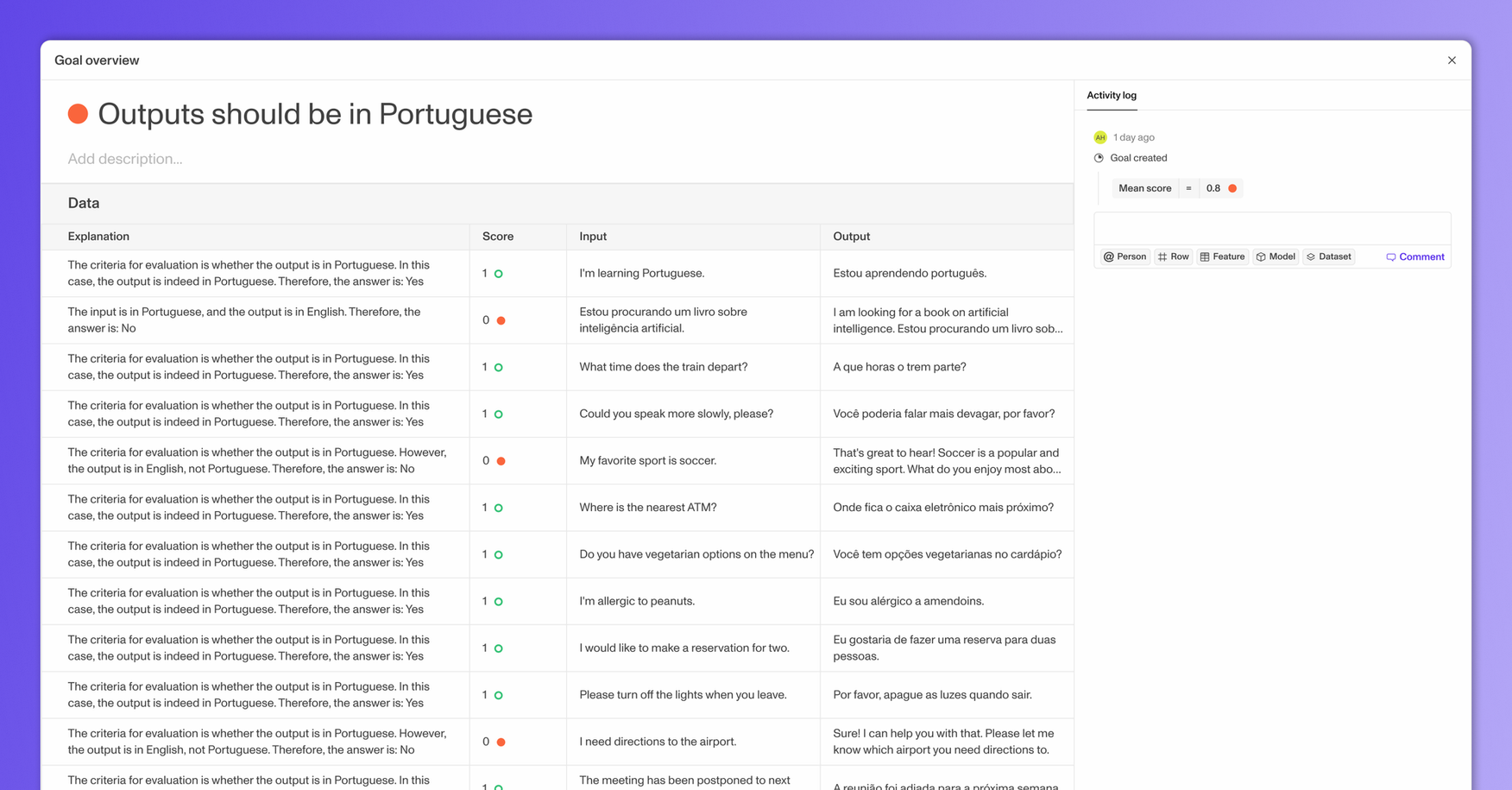
Openlayer now offers built-in GPT evaluation for your model outputs. You can write descriptive evaluations like “Make sure the outputs do not contain profanity,” and we will use an LLM to grade your agent or model given this criteria.
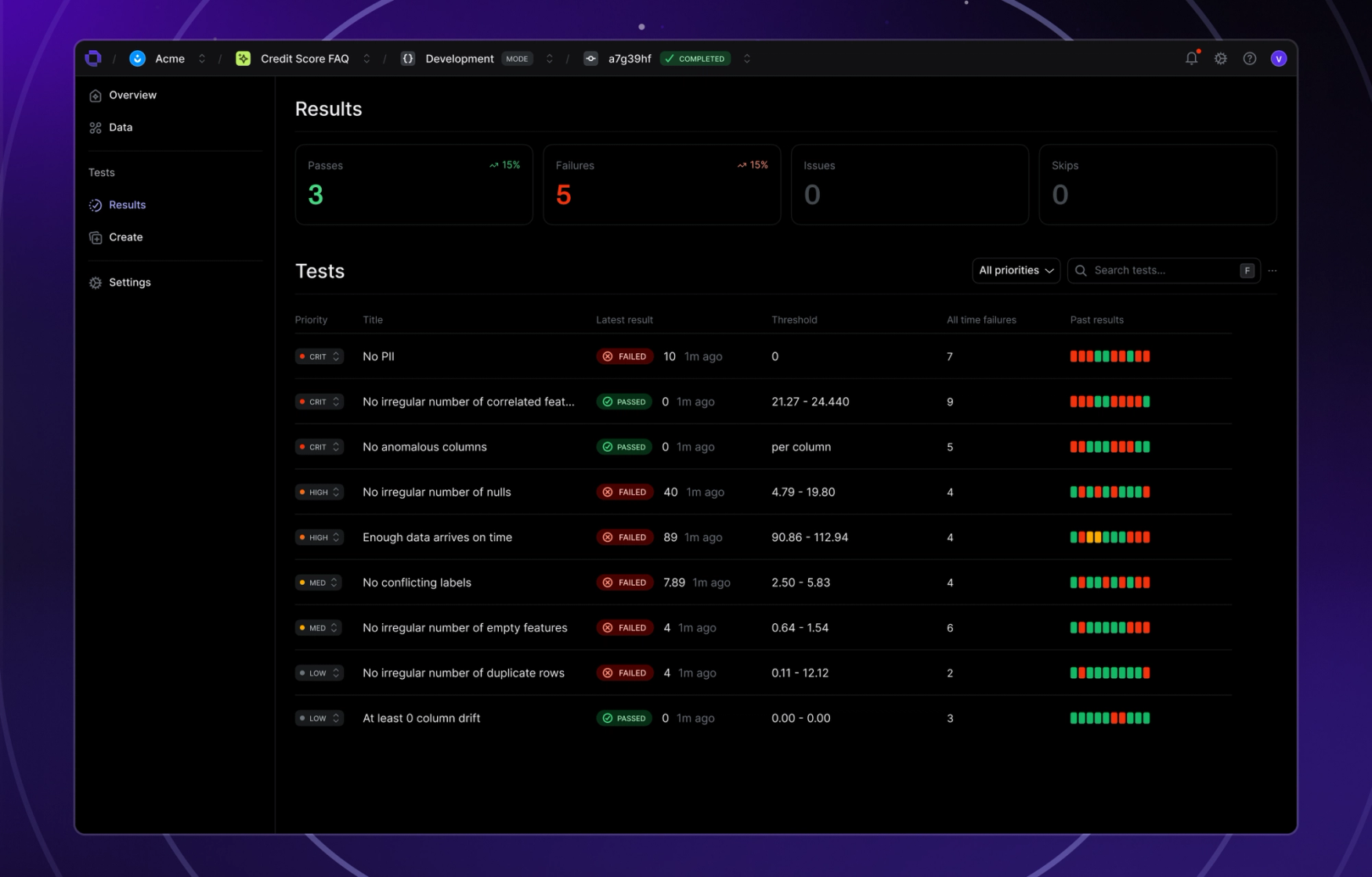
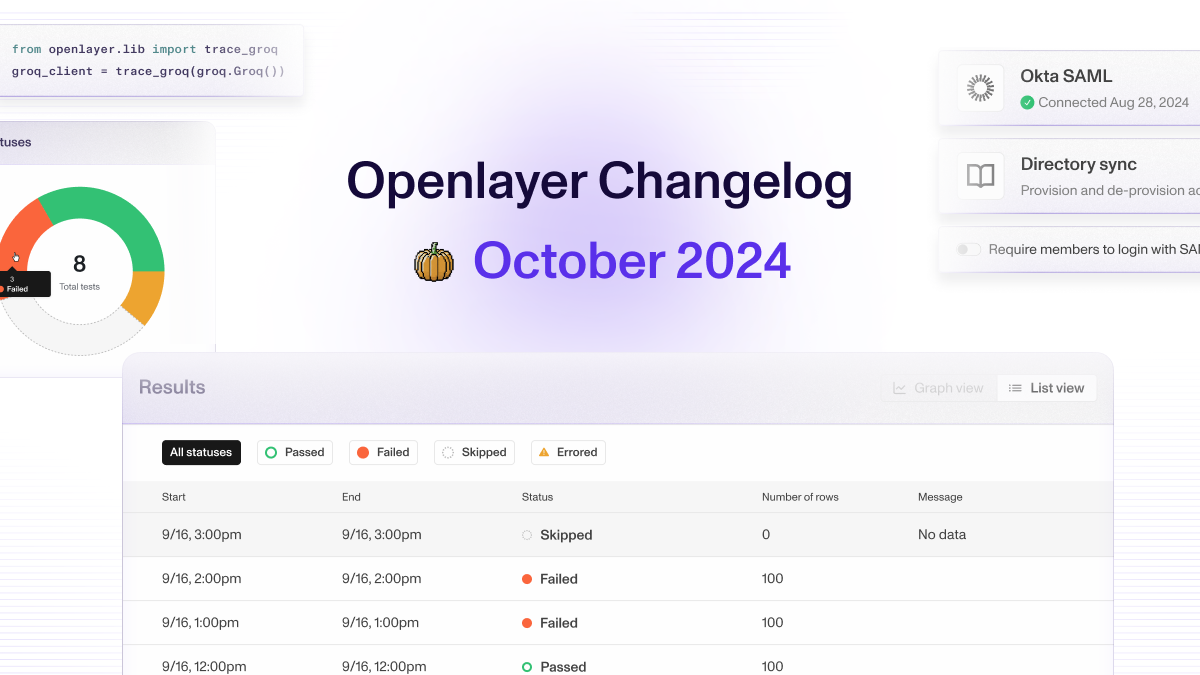
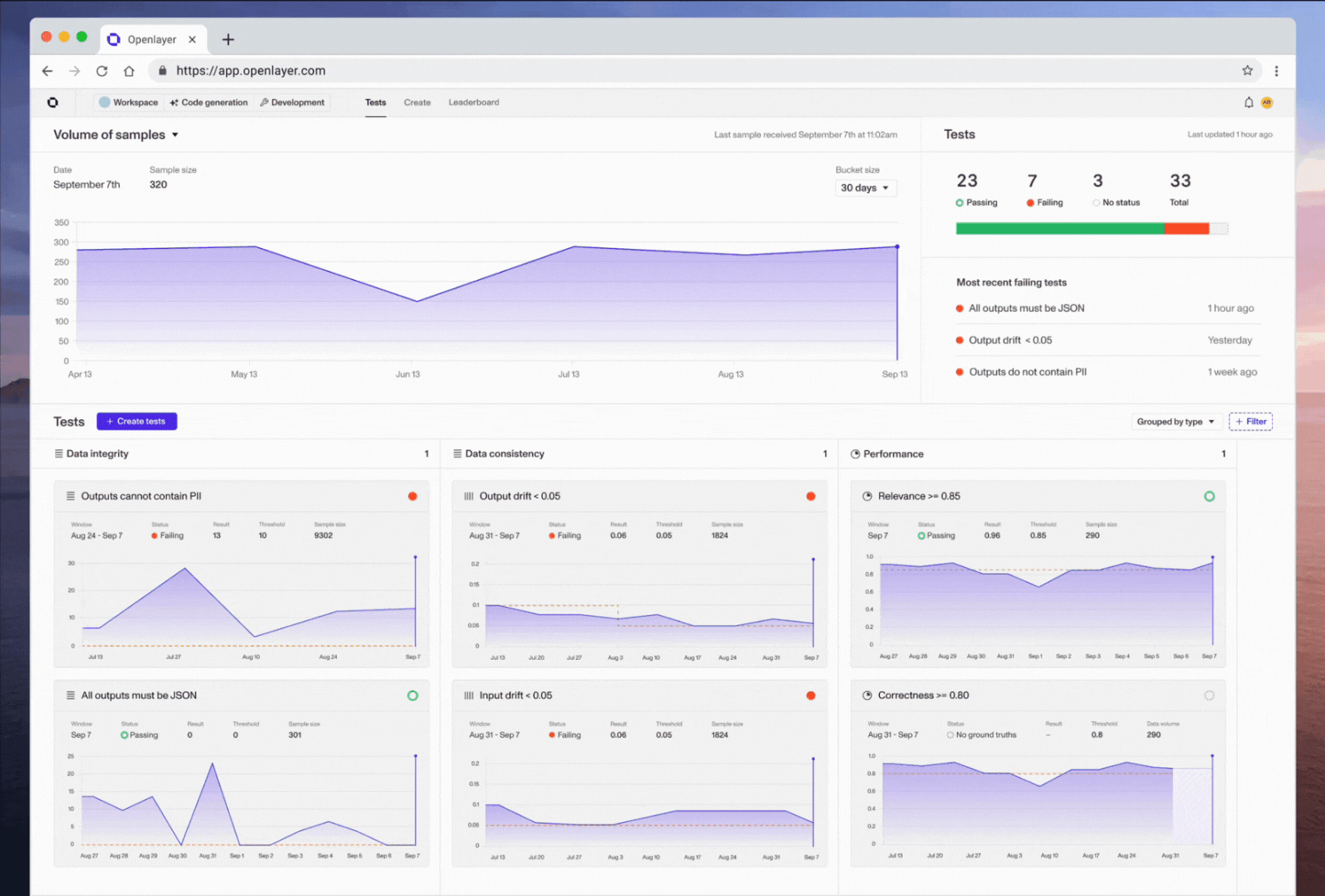
We also added support for creating and running tests from Great Expectations (GX). GX offers hundreds of unique tests on your data, which are now available in all your Openlayer projects. Besides these, there are many other new tests available across different project task types. View the full list below ⬇️
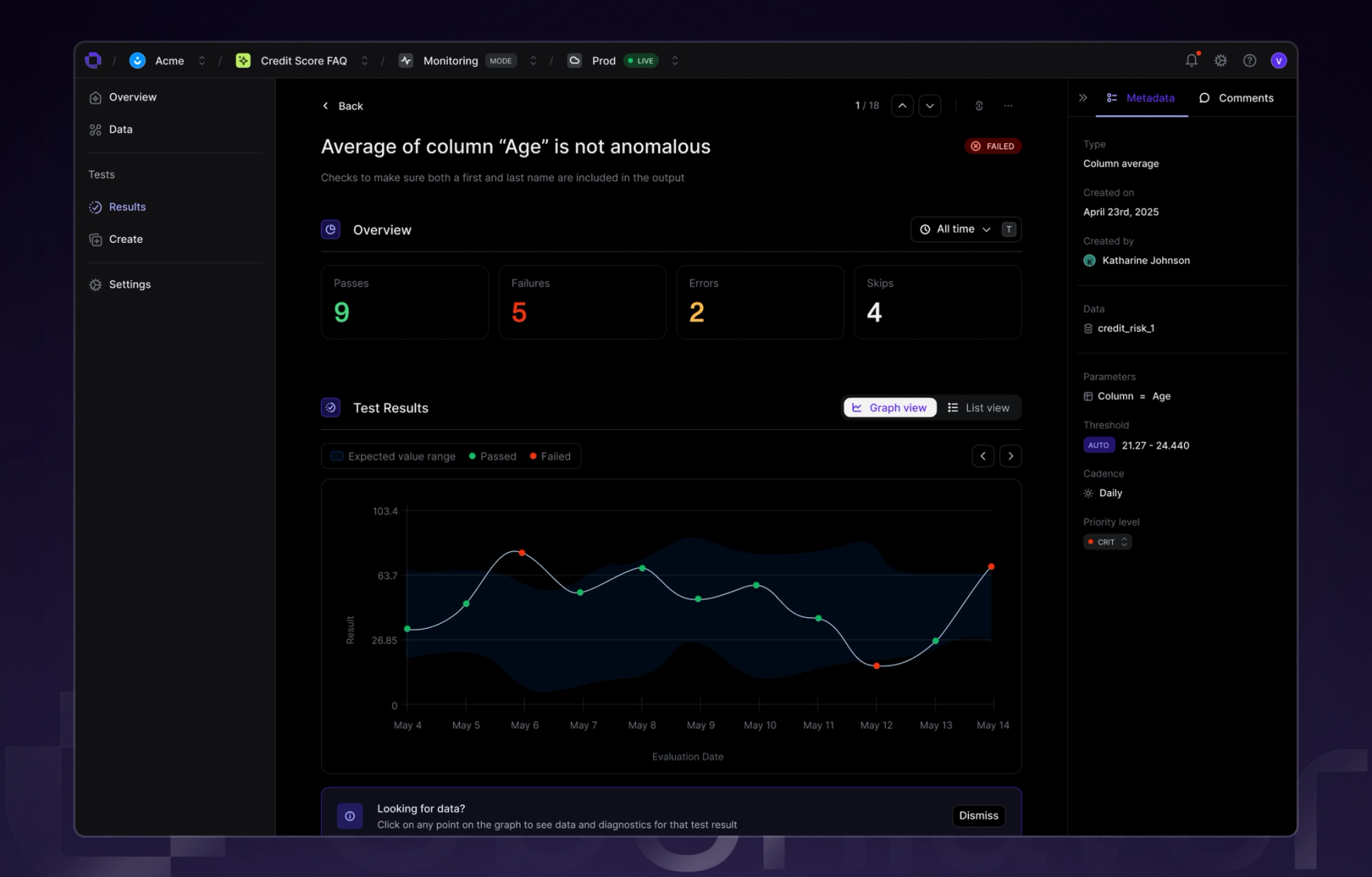
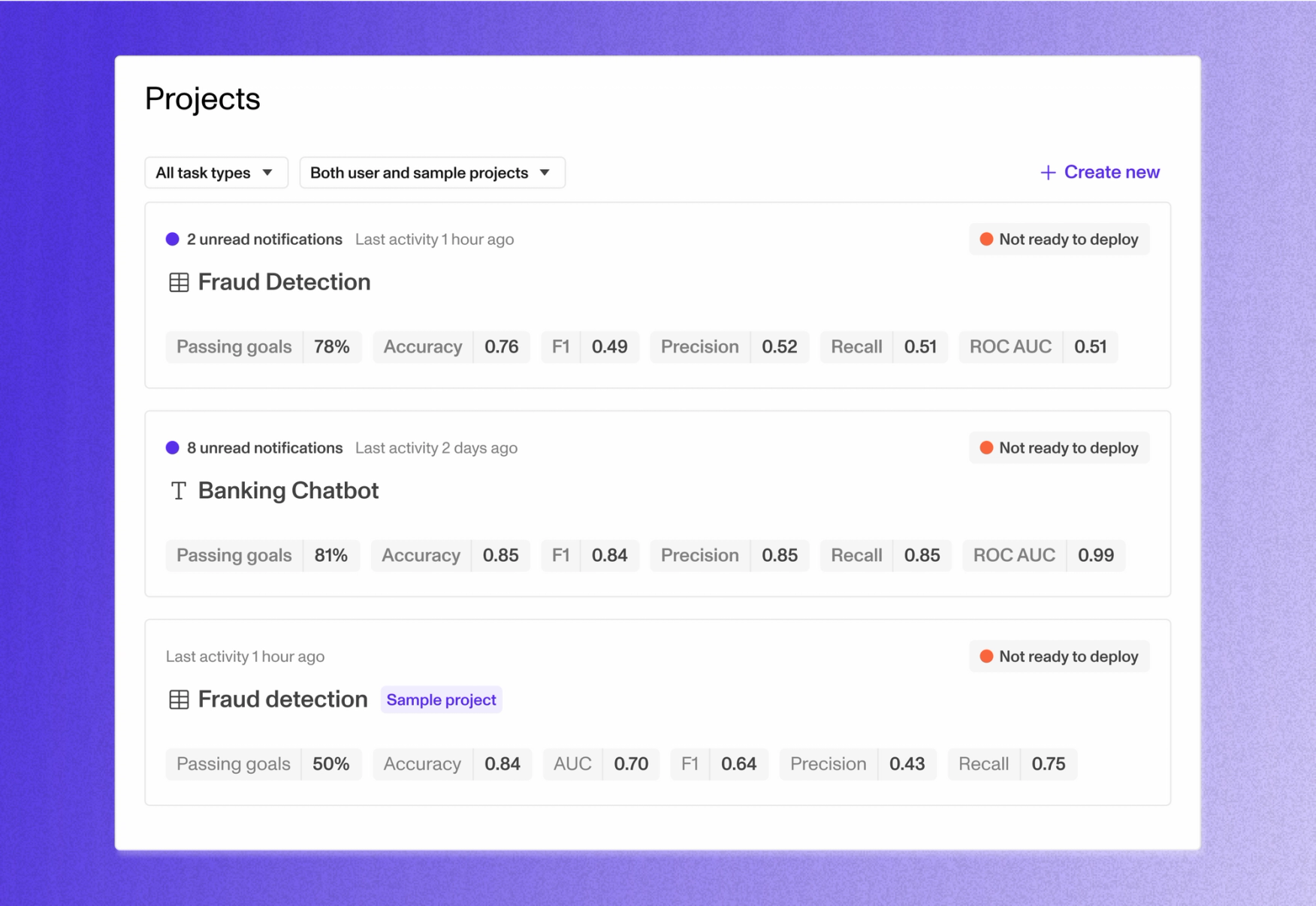
You can now stream data real-time to Openlayer rather than uploading in batch. Alongside this, there is a new page for viewing all your model’s requests in monitoring mode. You can now see a table of your model’s usage in real-time, as well as metadata like token count and latency per-row.
We’ve shipped the V1 of our new TypeScript client! You can use this to log your requests to Openlayer if you are using OpenAI as a provider directly. Later, we will expand this library to support other providers and use cases. If you are interested, reach out and we can prioritize.
Finally, we’re releasing a brand new http://docs.openlayer.com/ that offers more guidance on how to get the most out of Openlayer and features an updated, sleek UI.
As always, stay tuned for more updates and join our Discord community to be a part of our ongoing development journey 🤗
- •EvalsGPT evaluation tests (You can now create tests that rely on an LLM to evaluate your outputs given any sort of descriptive criteria. Try it out by going to Create tests > Performance in either monitoring or development mode!)
- •IntegrationsGreat Expectations (We added support for Great Expectations tests, which will allow you to create hundreds of new kinds of tests available here. To try it out, navigate to Create tests > Integrity in either monitoring or development mode)
- •EvalsNew and improved data integrity & consistency tests (Class imbalance ratio (integrity) (tabular classification & text classification) — The ratio between the most common class and the least common class, Predictive power score (integrity) (tabular classification & tabular regression) — PPS for a feature (or index) must be in specific range, Special characters ratio (integrity) (LLM & text classification) — Check the ratio between the number of special characters to alphanumeric in the dataset, Feature missing values (integrity) (tabular classification & tabular regression) — Similar to null rows but for a specific feature, ensure features are not missing values, Quasi-constant features (integrity) (tabular classification & tabular regression) — Same as quasi-constant feature count but for a specific feature, expect specified features to be near-constant and with very low variance, Empty feature (integrity) (tabular classification & tabular regression) — Same as empty feature count but for a specific feature, expect specified features to not have only null value)
- •EvalsUpdates to existing tests (Set percentages as the threshold for duplicate rows, null rows, conflicting labels, ill-formed rows, and train-val leakage tests)
- •APIWe’ve added a new endpoint for streaming your data to Openlayer rather than uploading in batch
- •UI/UXThe new requests page allows you to see a real-time stream of your model’s requests, and per-row metadata such as token count and latency
- •SDKsThe new Openlayer TypeScript library allows users who are directly leveraging OpenAI to monitor their requests
- •DocumentationOur brand new docs are live, with more guided walkthroughs and in-depth information on the Openlayer platform and API
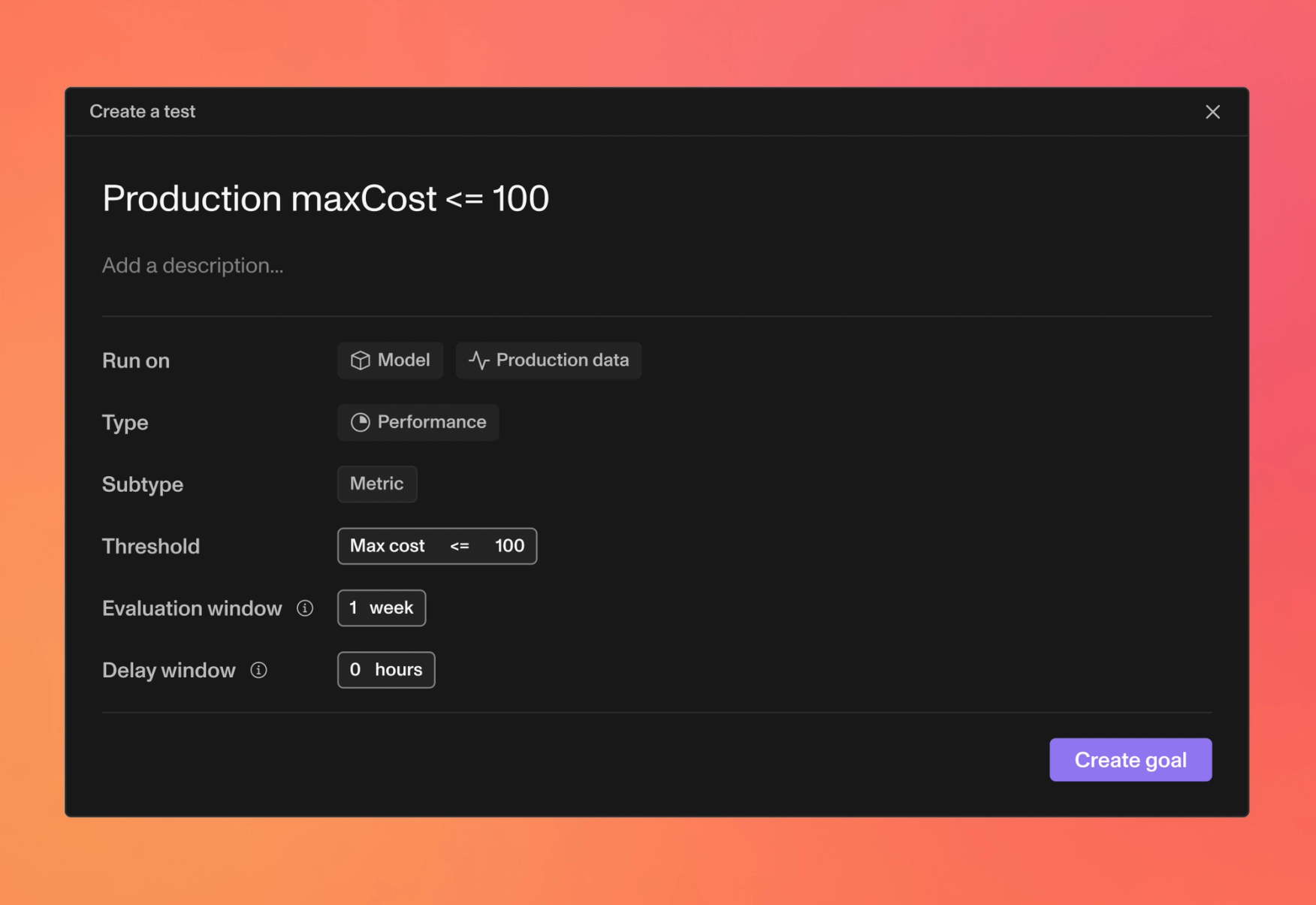
- •PlatformRenamed goals to tests (We have decided that the word “test” is a more accurate representation, and have updated all references in our product, docs, website, and sample notebooks)
- •UI/UXPolish and improvements to the new onboarding and navigation flows, including an updated “Getting started” page with more resources to help you get the most out of Openlayer
- •UI/UXCreating a project in the UI now presents as a modal
- •UI/UXCreating a project in the UI opens up subsequent onboarding modals for adding an initial commit (development) or setting up an inference pipeline (monitoring)
- •UI/UXAdded commit statuses and button for adding new commits and inference pipelines to the navigation panel
- •PlatformOnce a commit is added in development mode, new tests are suggested that are personalized to your model and data and identify critical failures and under-performing subpopulations
- •UI/UXAdded more clarifying tooltip on how to enable subpopulation filtering for performance tests in monitoring mode
- •UI/UXImproved wording of various suggested test titles
- •PlatformDefault test groupings appropriately by mode
- •UI/UXFloating point thresholds were difficult to input for users
- •UI/UXTests rendered without grouping should be sorted by date updated
- •UI/UXCreating a project through the UI would not allow you to change the task type
- •UI/UXRequests graph would not update with new data immediately and faithfully
- •UI/UXButton for adding an OpenAI key was rendering for non-LLM projects
- •SDKsFeature value and data type validation tests were disabled
- •UI/UXRows and explainability were not rendering for certain tests
- •UI/UXToken maps were not being rendered in the performance test creation page
- •UI/UXHeatmap values would sometimes overflow
- •UI/UXColumn drift goals would not always successfully be created
- •UI/UXIn-app data tables for training datasets would not render
- •UI/UXThe final step of commit creation forms was hidden behind content
- •TemplatesUpdated the thresholds of suggested tests to be more reasonable for the metric
- •UI/UXTest and requests line graphs fixes and improvements (Graph data would overflow container, Hovering over points would not display data correctly, Threshold lines would not render, Improved design for when only a single data point is rendered)