You can now click on any test to dive deep into the test result history. Select specific date ranges to see the requests from that time period, scrub through the graph to spot patterns over time, and get a full picture of performance.
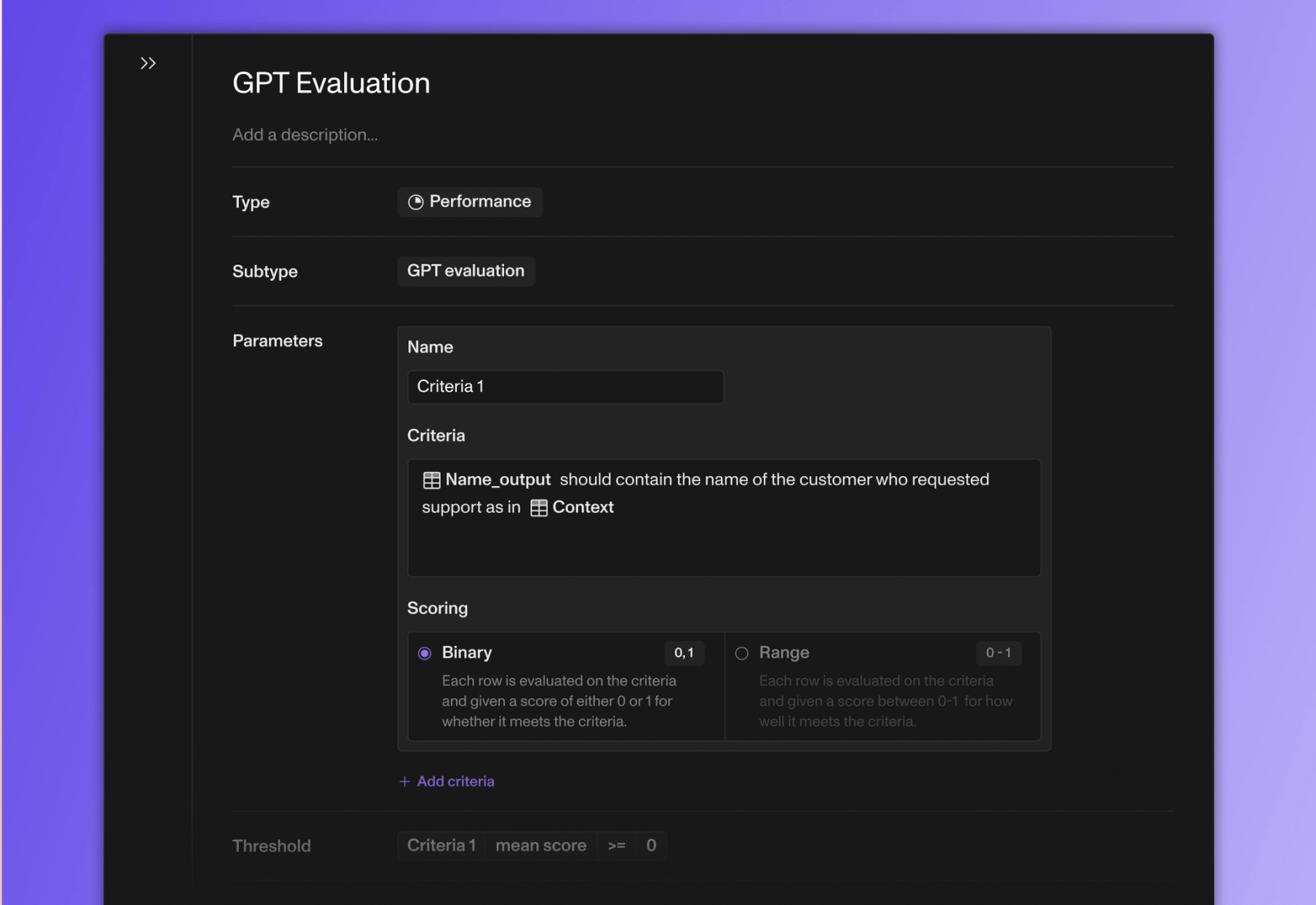
We’ve also added the ability to add multiple criteria to GPT evaluation tests. Let’s say you’re using an LLM to parse customer support tickets and want to make sure every output contains the correct name, email address and account ID for the customer. You can now set a unique threshold for each of these criteria in one test.
Features
•UI/UXScrub through the entire history of test results in the individual test pages (See which requests were evaluated per each evaluation window, See results and requests from a specific time period)
•EvalsImproved LLM-as-a-judge test (Add multiple criteria to a single test, Choose how you want each row to be scored against the criteria: on a range from 0-1, or a binary 0 or 1)
Improvements
•PerformanceBolster backend server to handle higher loads
•UI/UXTable headers no longer wrap
•UI/UXNull columns hidden in data table
•UI/UXTest metadata moved to the side panel so that the test results graph and data are viewed more easily
•UI/UXSkipped test results are rendered with the most recent result value
•UI/UXTest results graph height increased in the page for an individual test
•UI/UXDate labels in tests results graph improved
•PerformanceOnly render rows that were evaluated for GPT metric threshold tests
•UI/UXTest card graphs no longer fla
Fixes
•UI/UXResults graph was not sorted correctly
•UI/UXTest results graph did not overflow properly
•UI/UXTest results graph did not render all data points
•PlatformEmpty and quasi-constant features test creation was broken
•UI/UXUndefined column values now rendered as null
•UI/UXMost recent rows were not being shown by default
•UI/UXLabel chip in results graphs for string validation tests was not inline
•UI/UXTest results were not rendering properly in development mode
•UI/UXPlan name label overflowed navigation
•UI/UXButtons for exploring subpopulations was active even when no subpopulations existed
•UI/UXResults graph rendered loading indicator even after networking completed for skipped evaluations
•UI/UXRows for the current evaluation window were not rendered in test modals
•UI/UXCommit, metrics, and other tables were not rendering rows
•UI/UXDuplicate loading and empty placeholders rendered in monitoring mode
$ openlayer push
Stop guessing.
Ship with confidence.
The AI governance and observability platform
We value your privacy
We use cookies to enhance your browsing experience, serve personalized content, and analyze our traffic.