Trace system behavior, monitor cost and latency, and catch failures before your users do.
Core features
Explore the platform

Why it matters
When LLM systems fail, your reputation is at risk
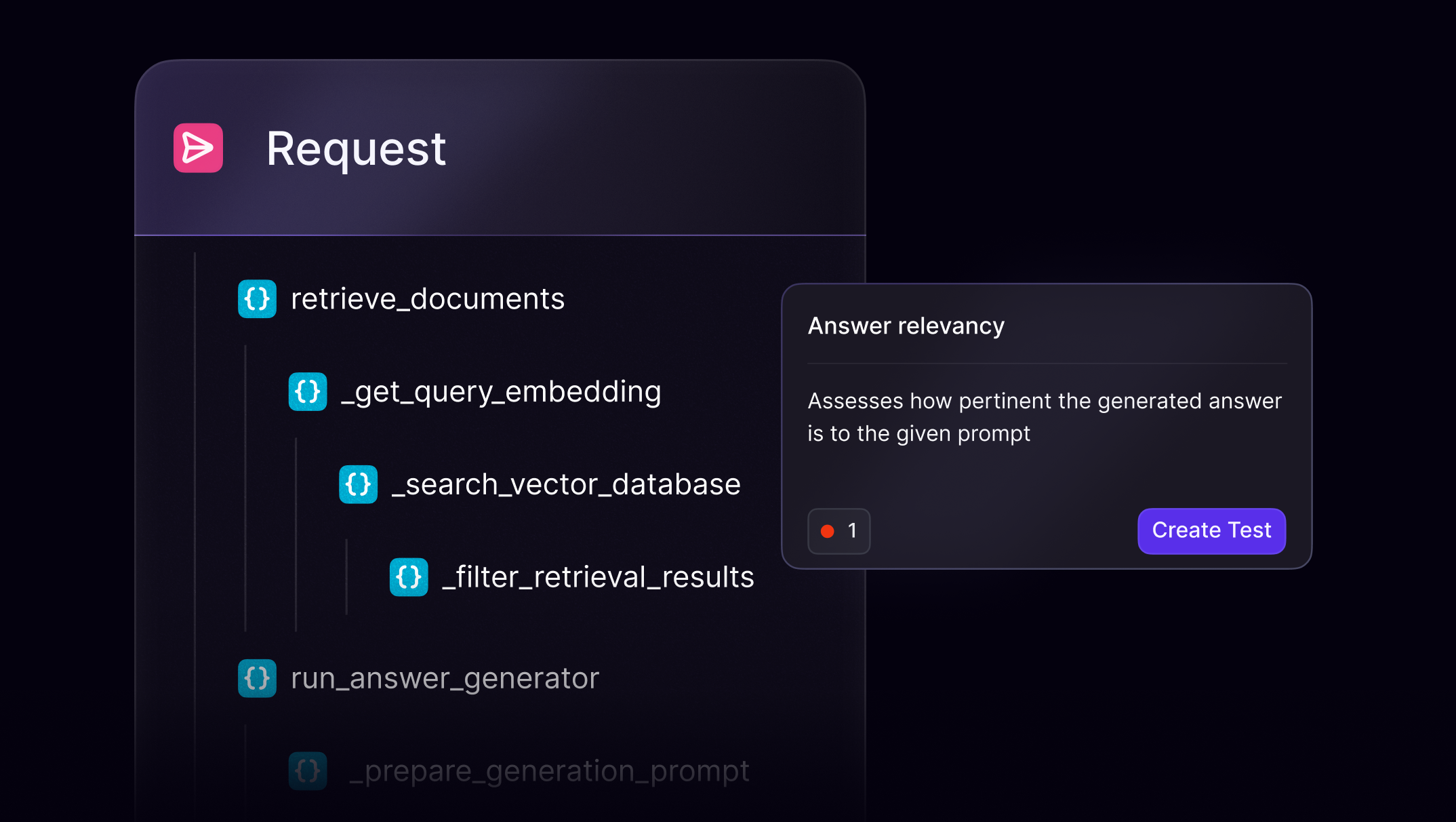
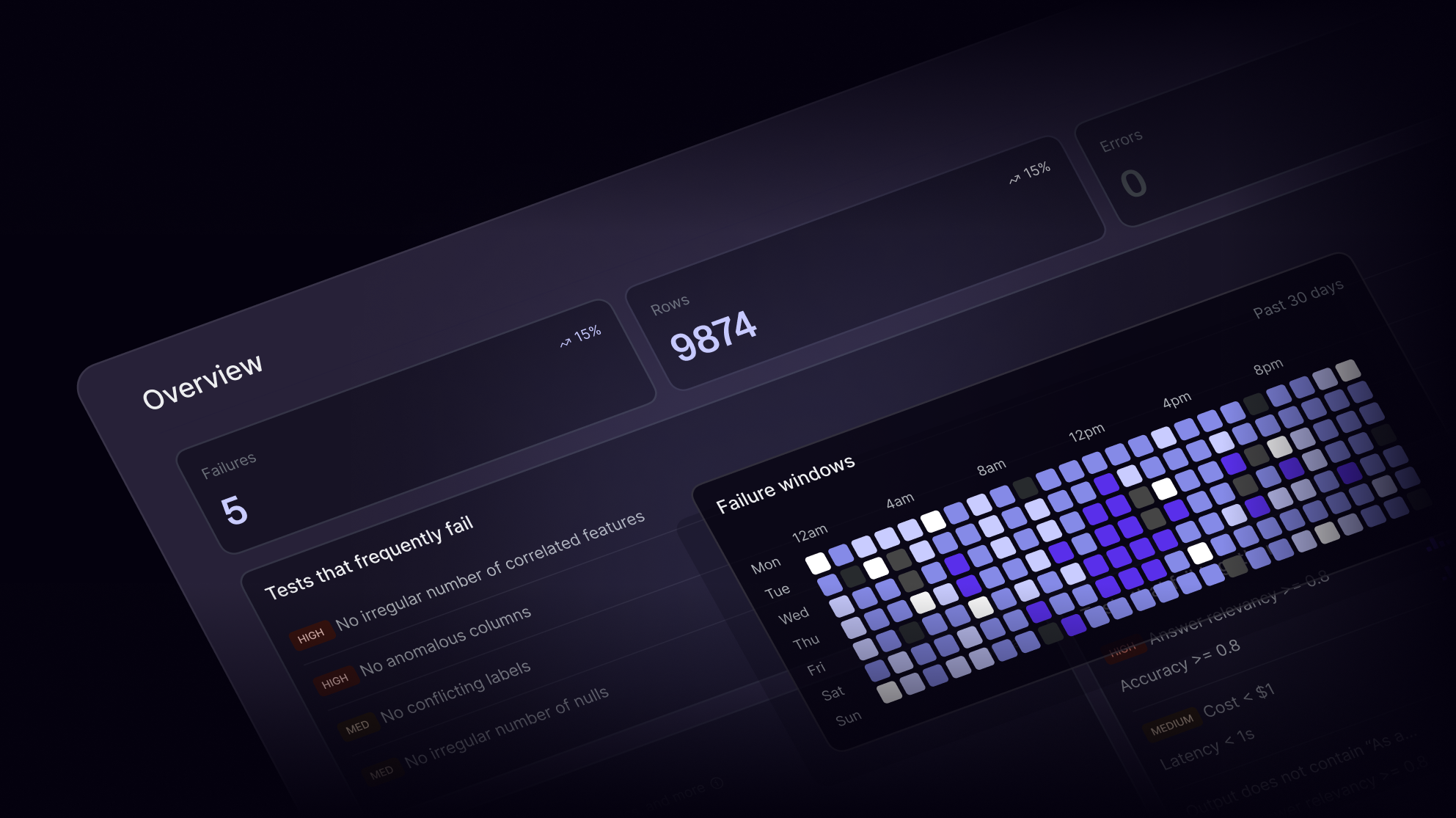
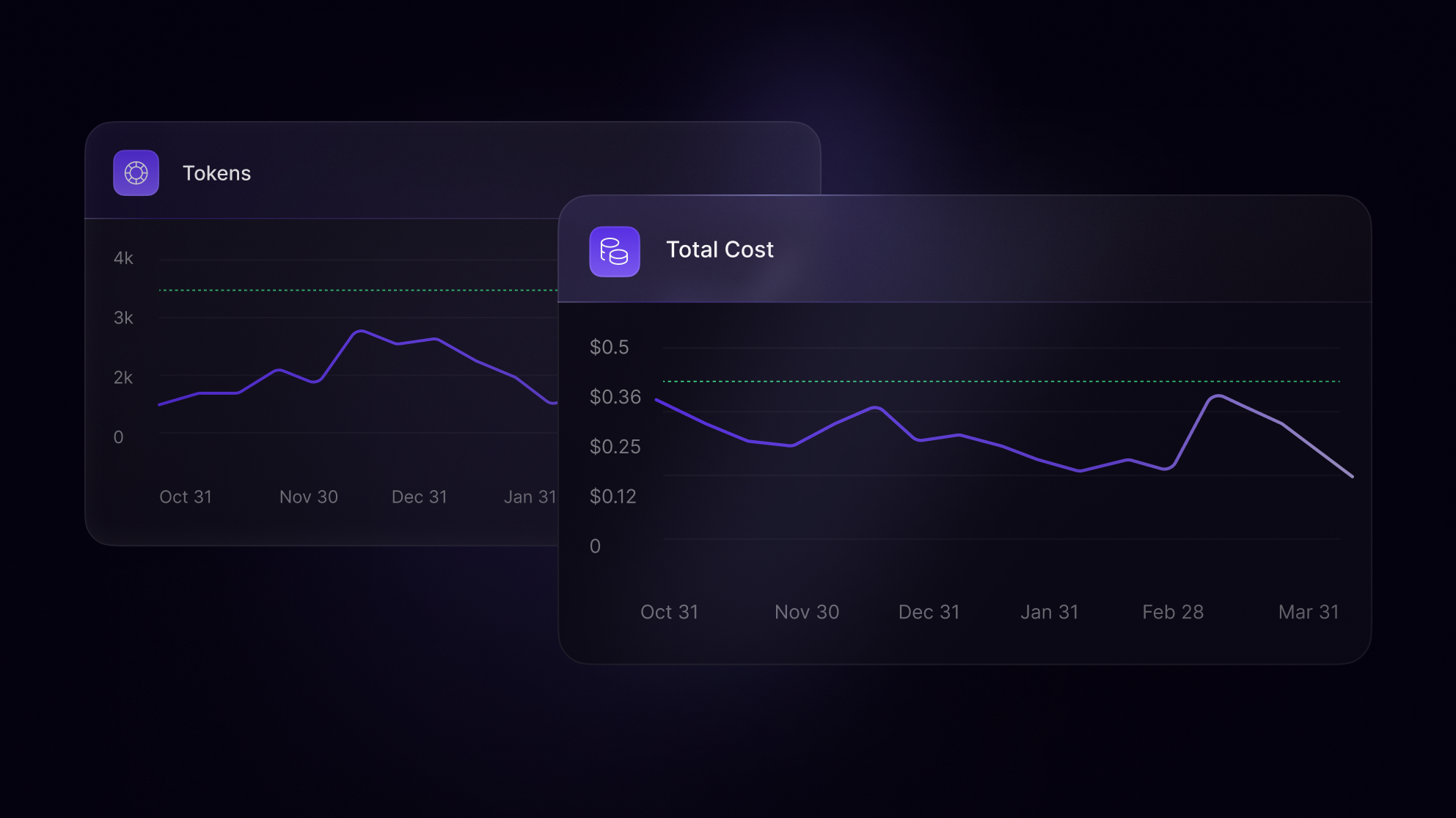
From toxic outputs to latency spikes and cost overruns, LLM-based systems present unique production challenges. Observability helps you trace, debug, and optimize your GenAI pipelines before things escalate.
Use cases
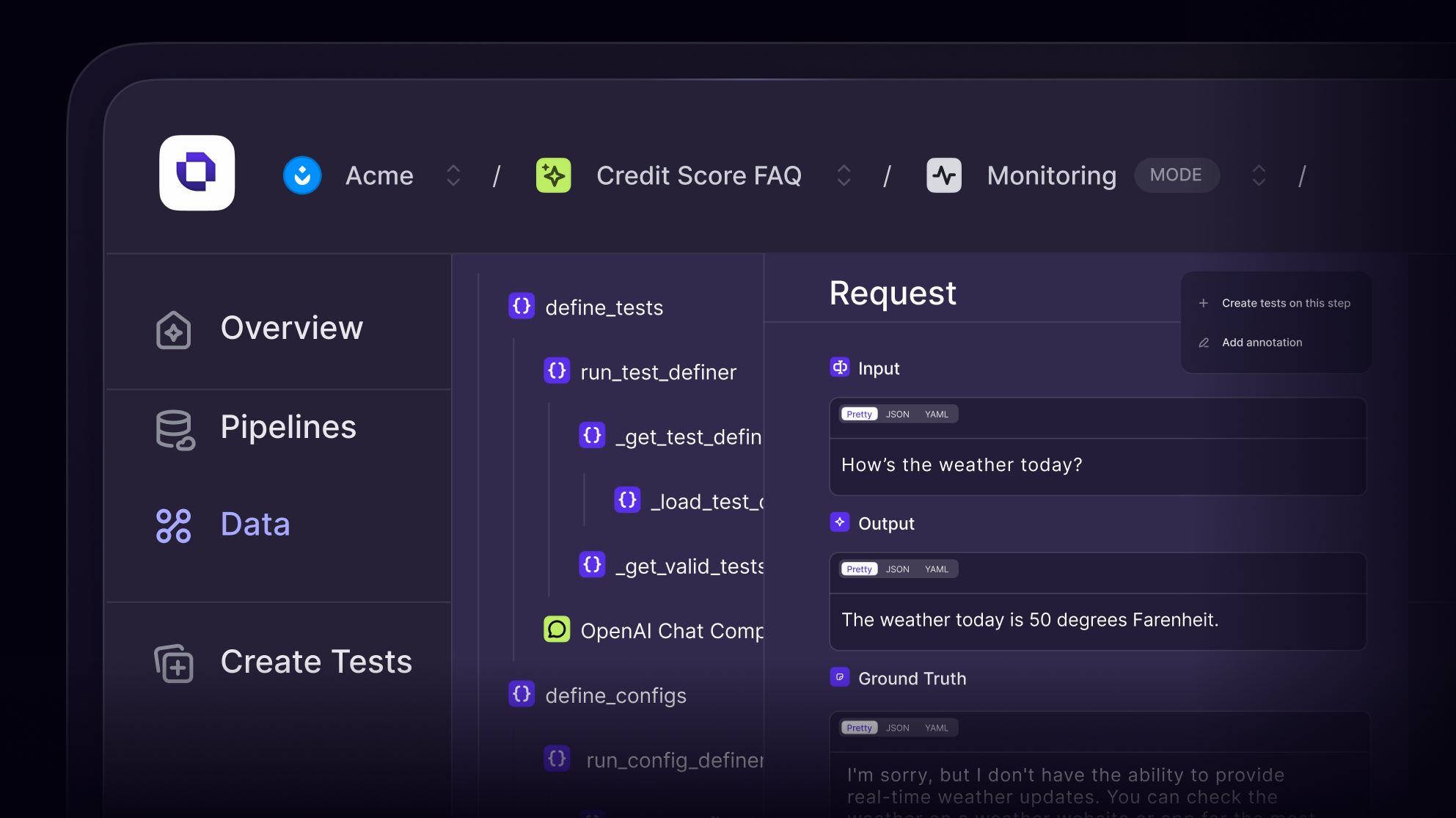
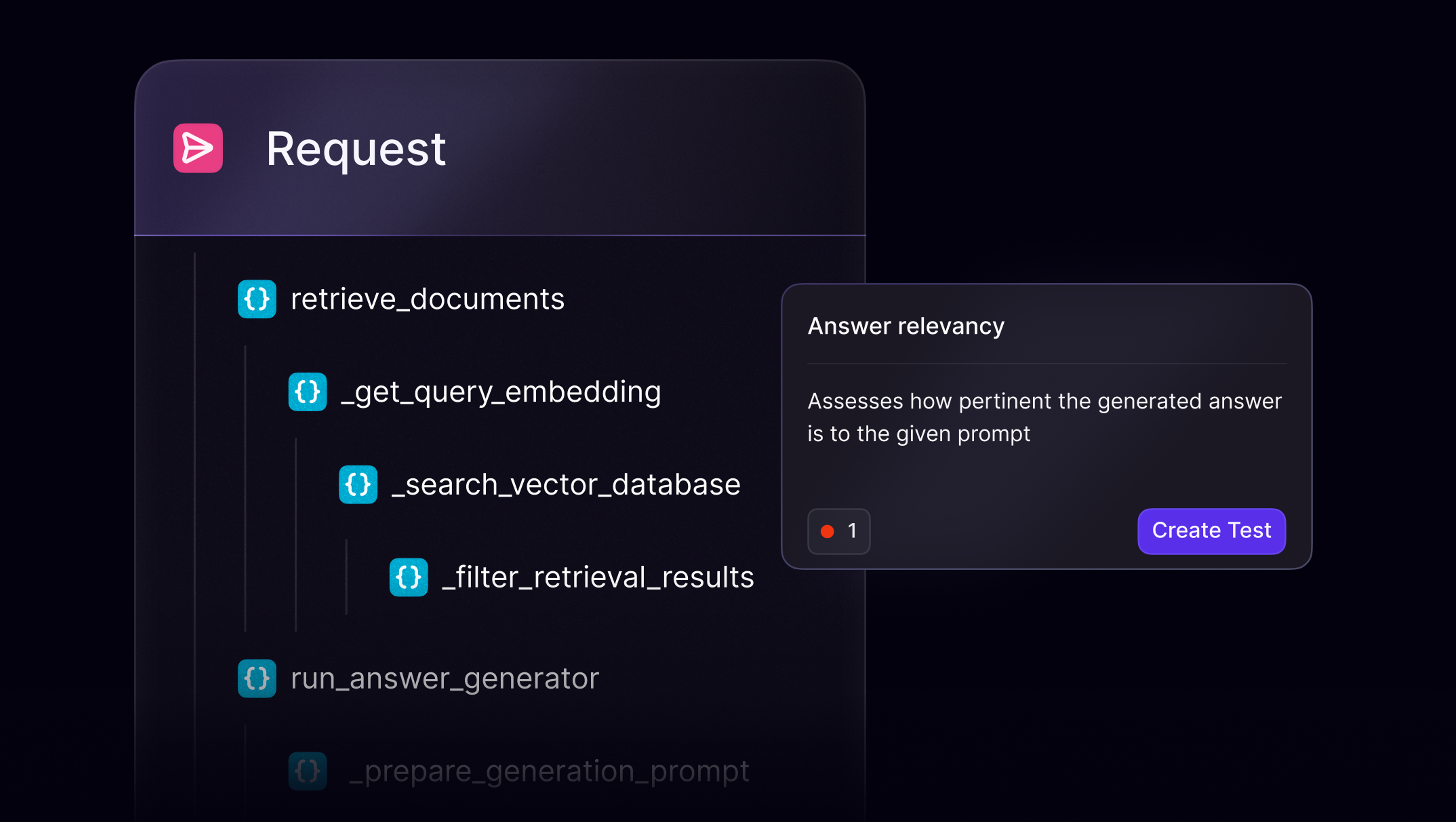
Observability for dynamic LLM workflows
Whether you're orchestrating agents, building retrieval-augmented generation (RAG) systems, or fine-tuning internal copilots, Openlayer gives you full visibility into system behavior, cost, and latency.
Why Openlayer
Built for modern GenAI operations
Integrations
Works across your GenAI stack
Openlayer integrates with OpenAI, LangChain, Anthropic, OpenTelemetry, and more. Connect to tracing tools and cloud infra. Deploy with zero vendor lock-in.

Customers
Visibility that builds trust
“We debugged a prompt injection issue in minutes—not days. Our GenAI systems are safer because of Openlayer.”
VP of Engineering at Healthcare Institution
FAQs
Your questions, answered
$ openlayer push