From agent hallucinations to planning failures, Openlayer helps you test and debug LLM agents with precision and visibility.
Why evaluating agents is challenging
Agents aren't just prompts, they're systems
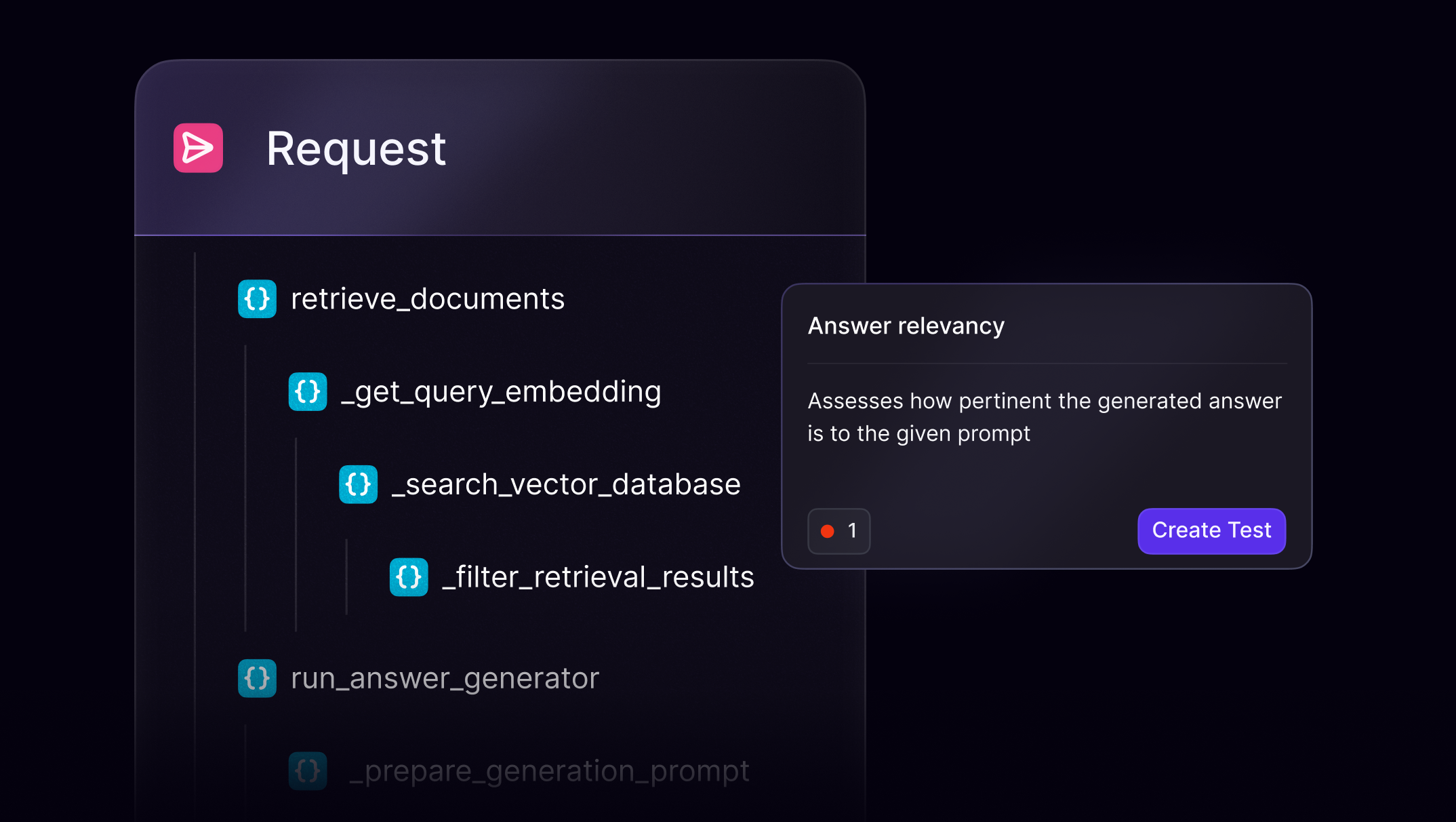
LLM agents operate through chaining, tool use, and reasoning steps. Evaluating them requires tracing not just final outputs, but every decision and interaction along the way.
What LLM agent evaluation involves
Track. Test. Trust.
Openlayer's approach
Make agent evaluation repeatable and reliable
Trace each step of an agent’s reasoning process
Evaluate tool outputs, transitions, and outcomes
Compare runs across chains, tools, and prompt versions
Tag failures and surface reproducible bugs
Compatible with LangChain, LlamaIndex, custom agents
FAQs
Your questions, answered
$ openlayer push