Test every prompt, trace every response, and validate every output with Openlayer.
LLM evaluation platform
Rigorous evaluation for GenAI and LLMs
Core features
Explore the platform
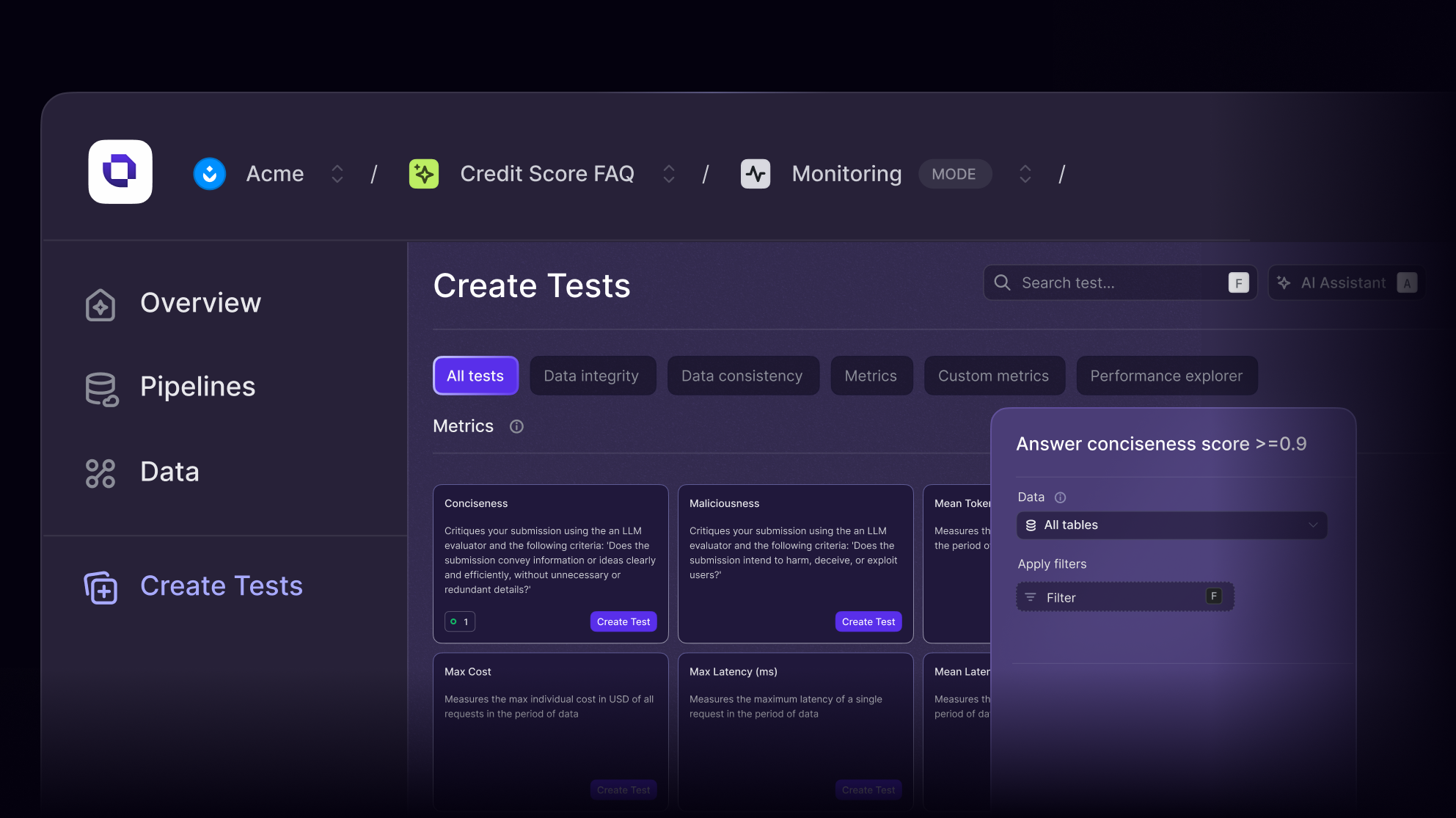
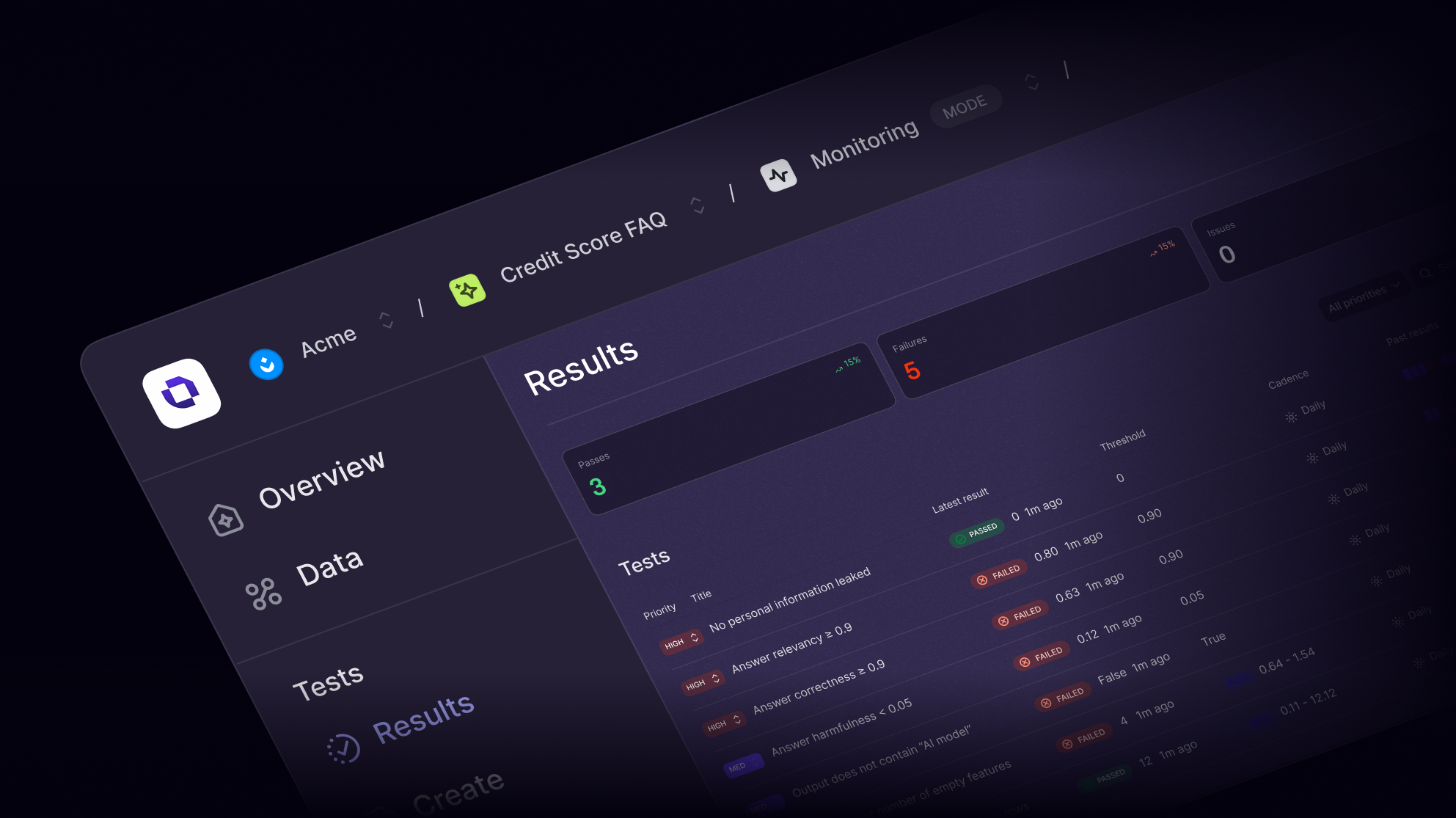

Why it matters
LLMs are powerful, but unpredictable
Hallucinations, inconsistent outputs, and unclear evaluation metrics make deploying LLMs risky. Without structured testing, teams are left guessing what works. Openlayer brings rigor to LLM evaluation so you can benchmark, iterate, and ship with confidence.
Use cases
Purpose-built for complex GenAI apps
Whether you're building AI copilots, summarization tools, or customer support agents, Openlayer helps you test performance across prompts, data types, and model settings, including hallucination, toxicity, relevance, and bias.
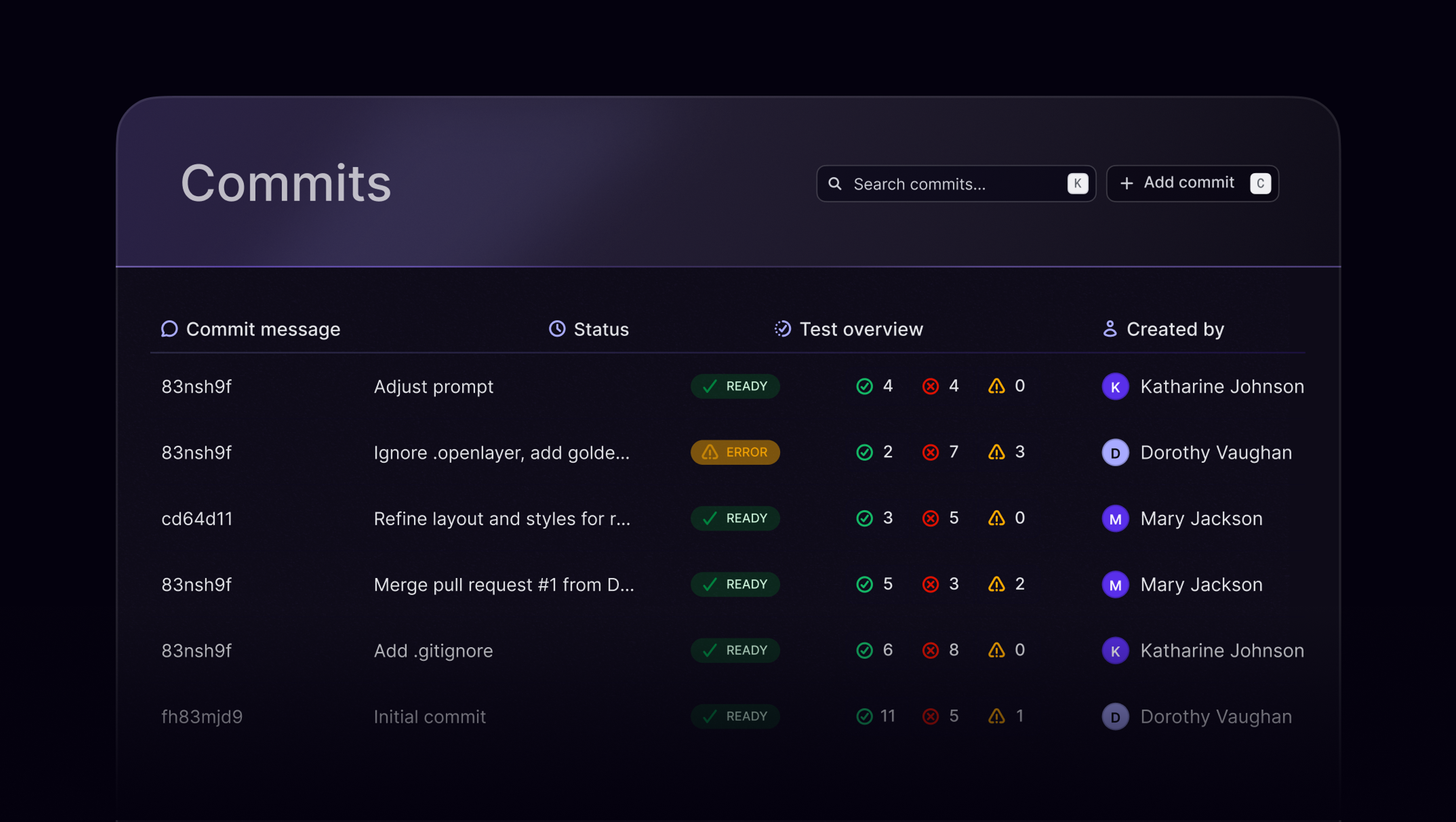
Why Openlayer
Standardize evaluation across GenAI systems
Integrations
Plug into your GenAI stack
Supports OpenAI, Anthropic, Hugging Face, LangChain, and more. Trigger tests via CLI or GitHub Actions. Integrates with prompt orchestration layers and analytics tools.

Customers
Confidence before launch
“We rolled out our chatbot with zero hallucinations in testing—and we couldn’t have done it without Openlayer.”
Sr. Software Engineer at Fortune 500 Financial Institution
FAQs
Your questions, answered
$ openlayer push