Test and validate every agentic system before it impacts production. Openlayer helps teams assess reliability, security, and behavior across dynamic workflows, catching risks like hallucinations, bias, and prompt injection before they spread.
Core features
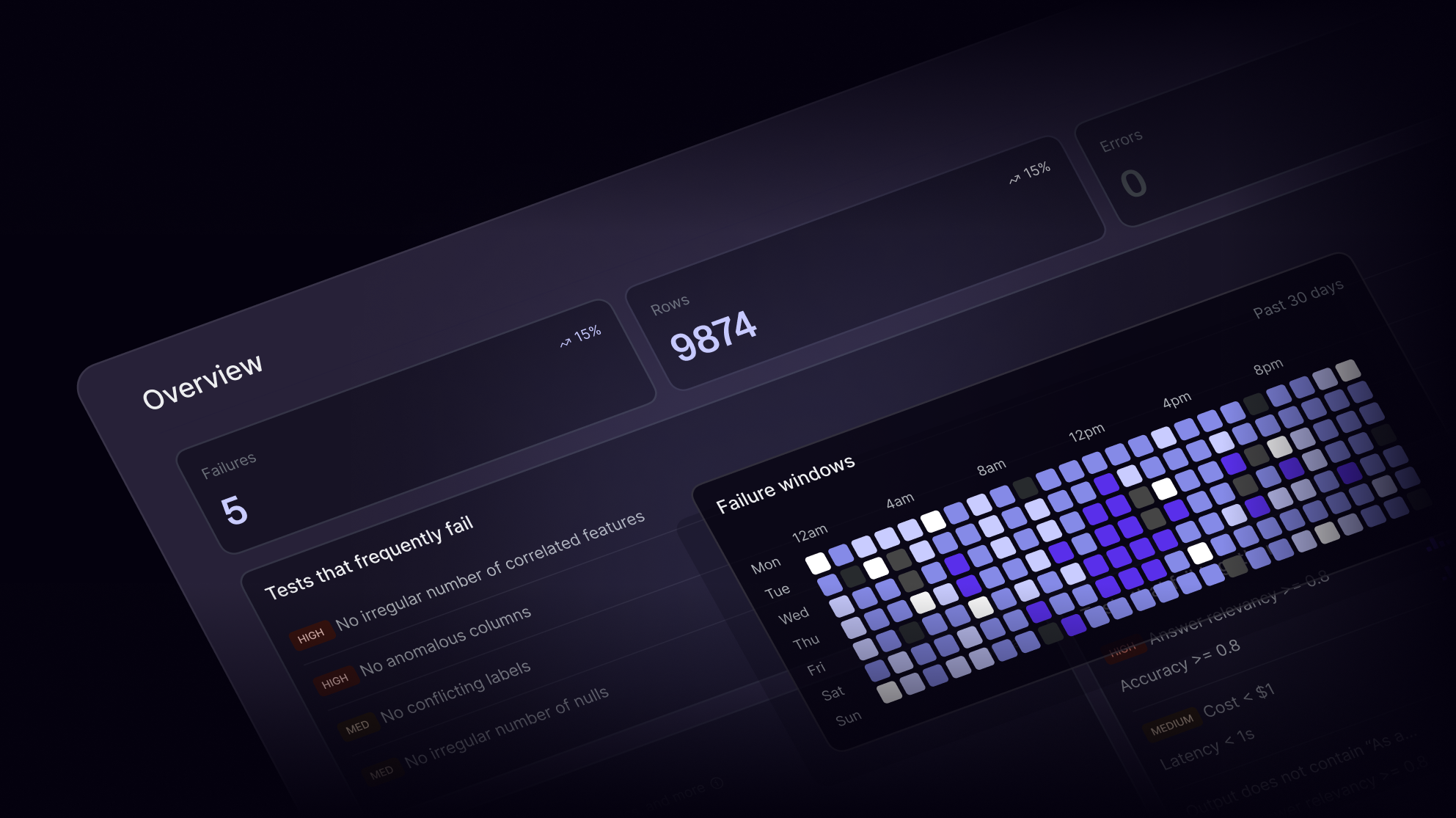
Built for agentic reliability
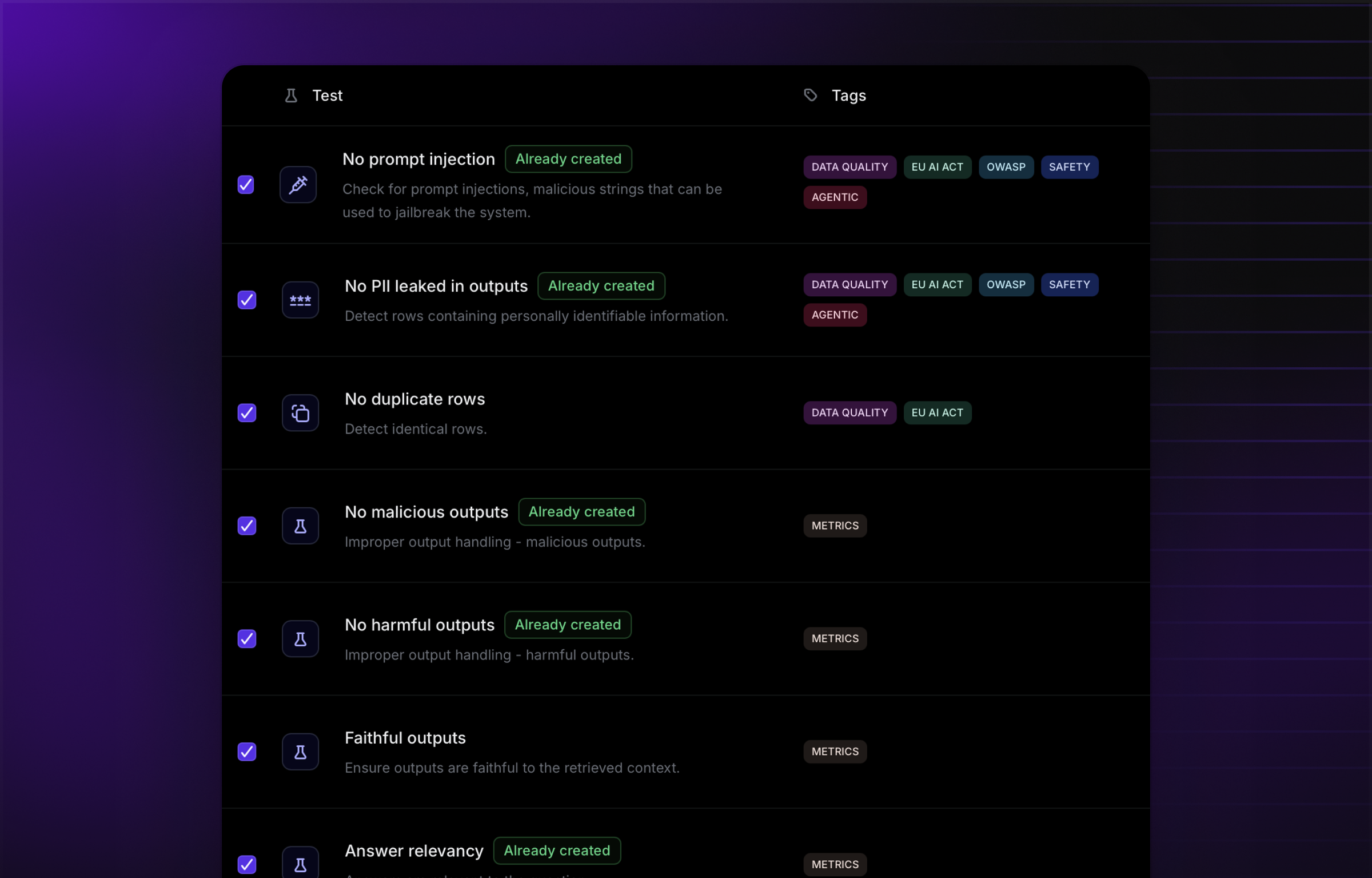
Openlayer provides a unified framework to evaluate autonomous and semi-autonomous AI agents across tools, data sources, and goals. Test responses, chain-of-thought execution, and policy adherence with precision.
Why it matters
Agent performance you can trust
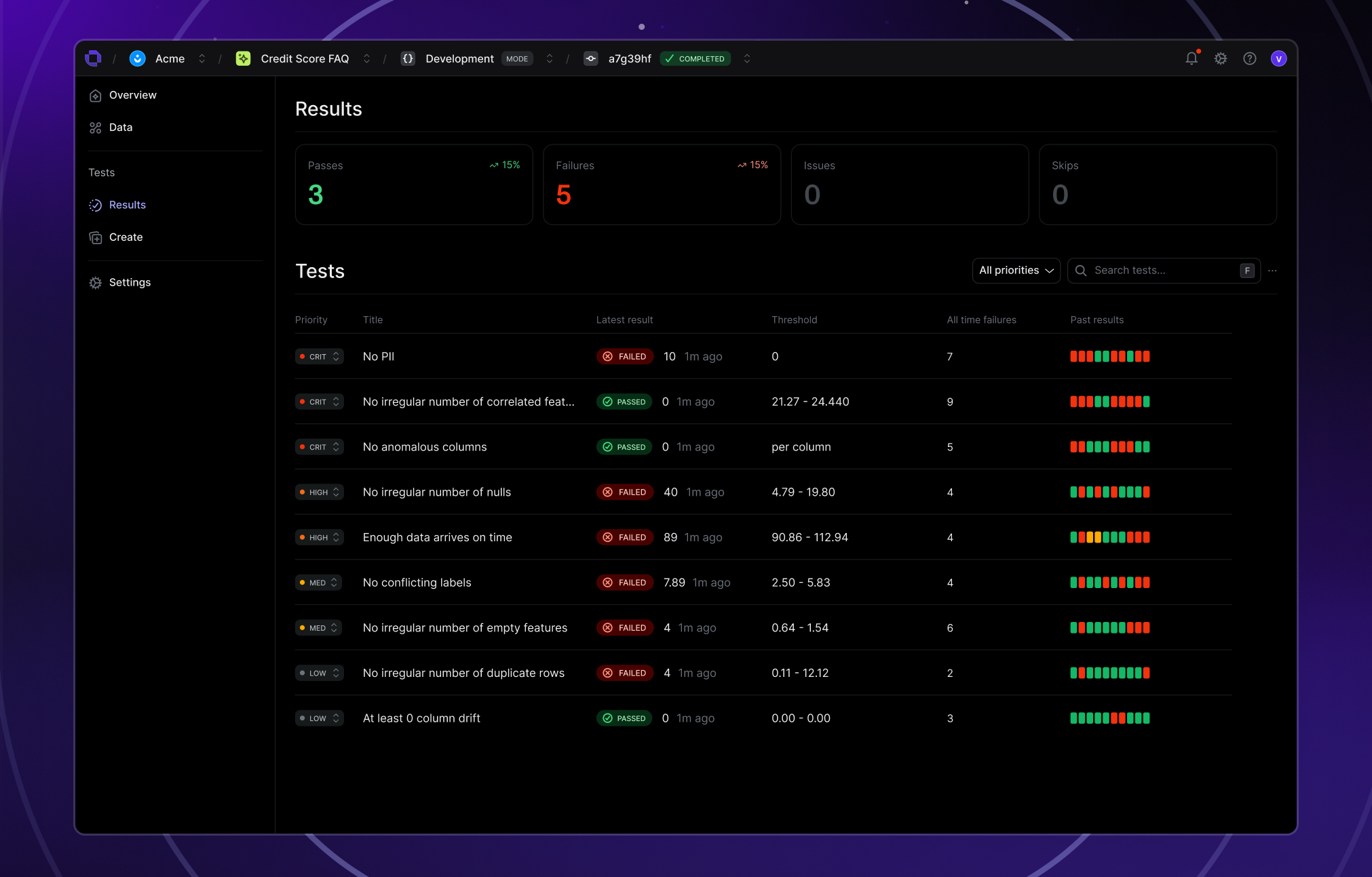
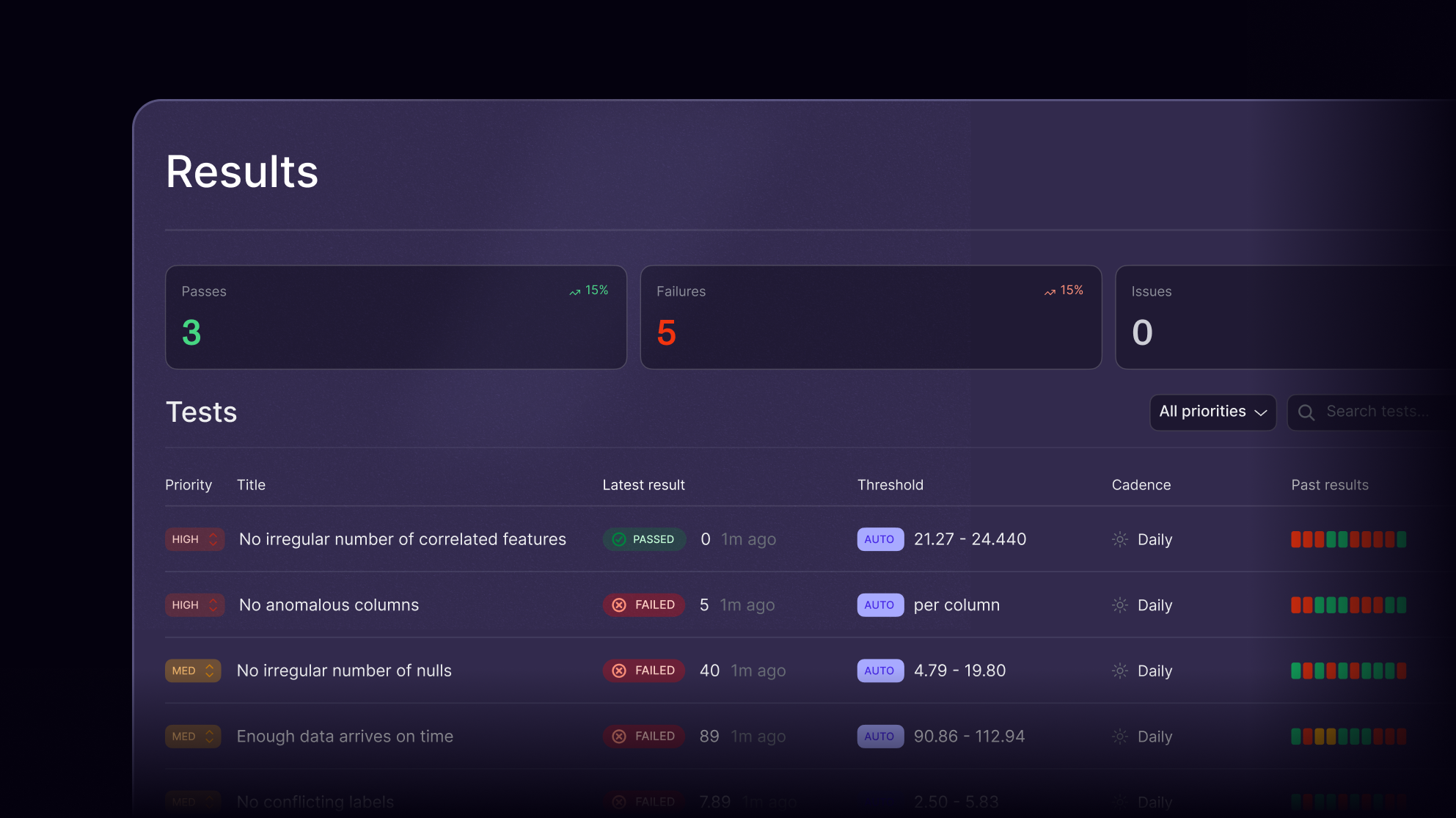
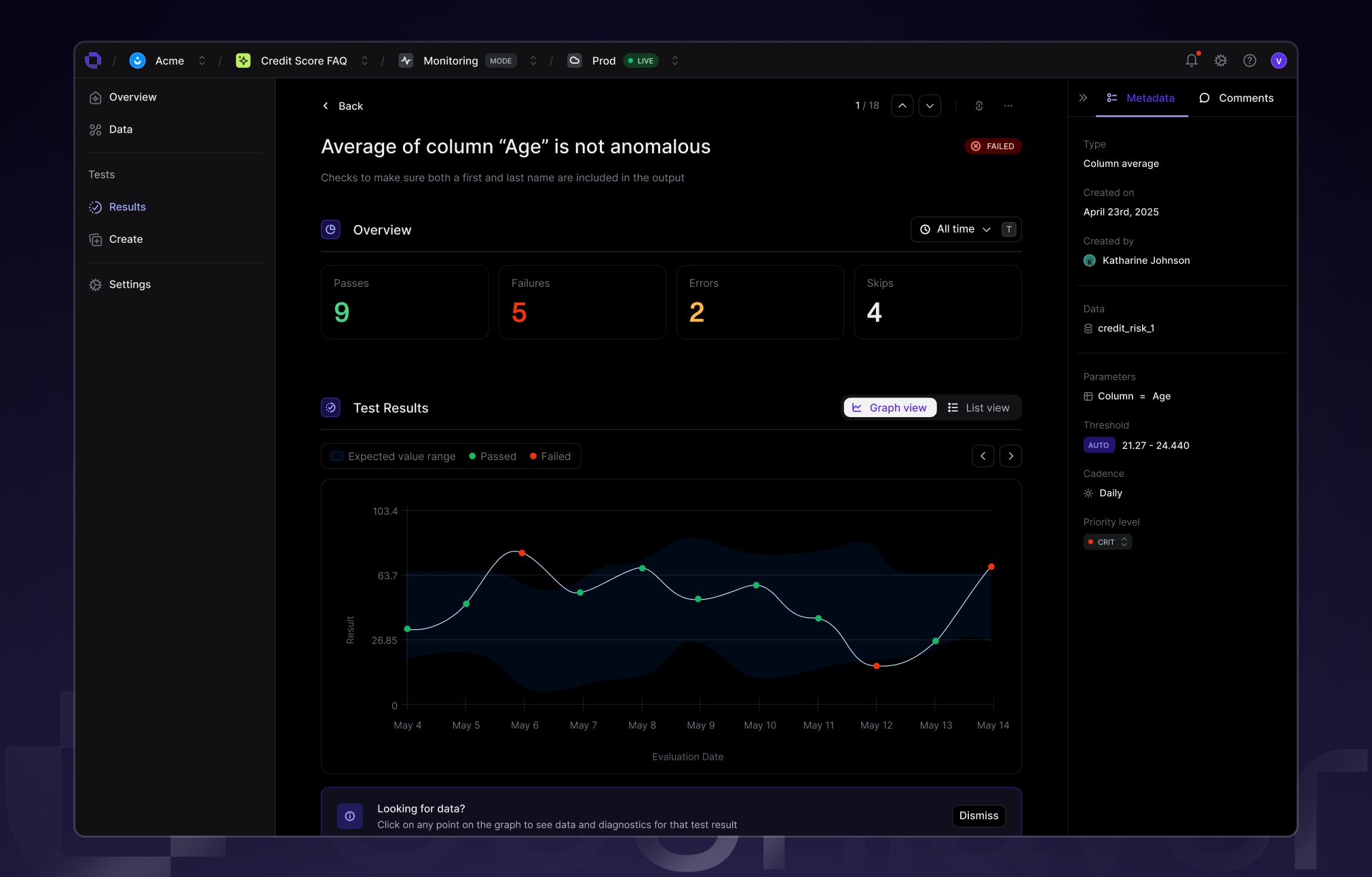
As AI agents automate workflows, trust becomes the new uptime. Evaluation helps prevent silent failures, from hallucinated actions to unsafe API calls, before agents interact with users or systems. With Openlayer, evaluation isn’t a one-off QA step, but a continuous confidence layer for every agent you build.
Use cases for agent evaluation
Use Cases
Why Openlayer
Reliability embedded in every agent workflow
Openlayer brings structure to the uncertainty of agentic systems, combining behavioral evaluation, security guardrails, and reliability scoring in one platform. Integrate testing into CI/CD pipelines, monitor regressions automatically, and maintain control as your agents evolve.
Frequently asked questions
FAQ
Customers
Trusted by teams who ship with confidence
$ openlayer push