How it works
1
Integrate with Openlayer
Use Openlayer’s SDKs to instrument your code.
The SDKs trace the requests your system receives and send them to the
Openlayer platform.It has streamlined integrations for popular frameworks such as OpenAI, Anthropic, LangChain, and many more.
But if you already use OpenTelemetry, or prefer to push events directly, you can send data using the REST APISee the Instrument your code guide for details.
2
View the traces
Once instrumented, every incoming request is published as a trace in the Openlayer platform.A trace shows the full lifecycle of a request — including inputs, outputs, intermediate steps,
and metadata.
You can view them on the Data page inside your project.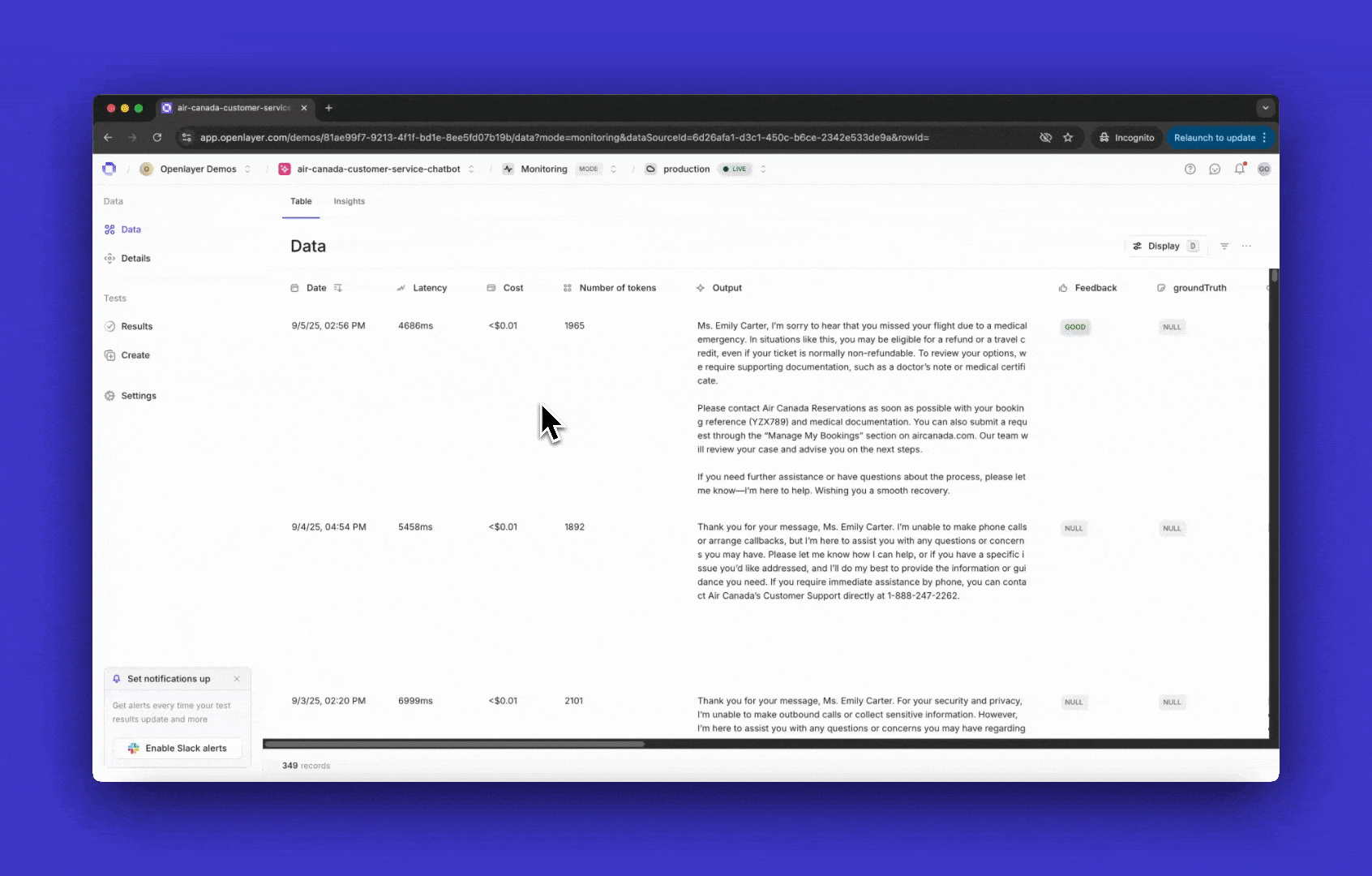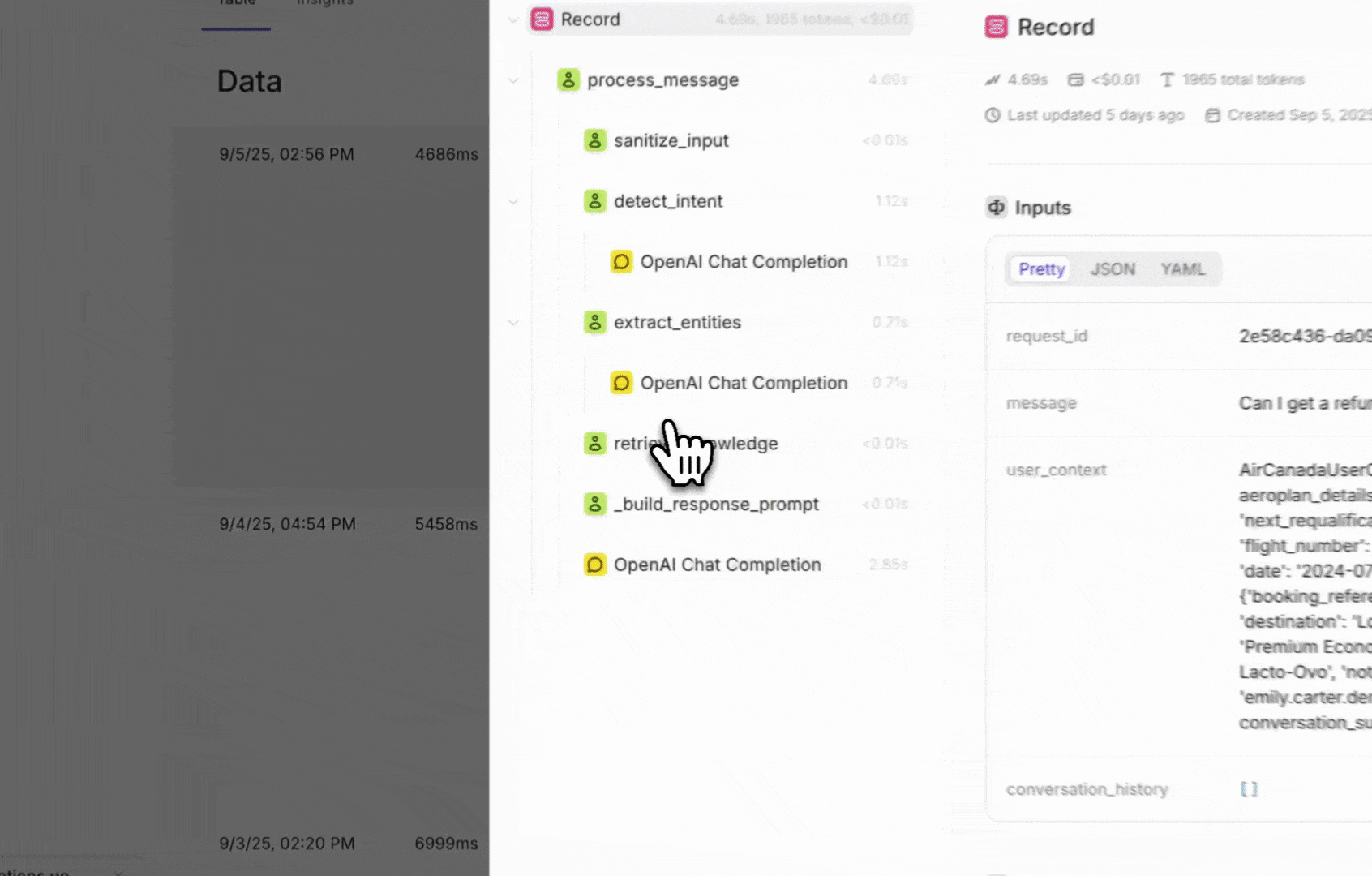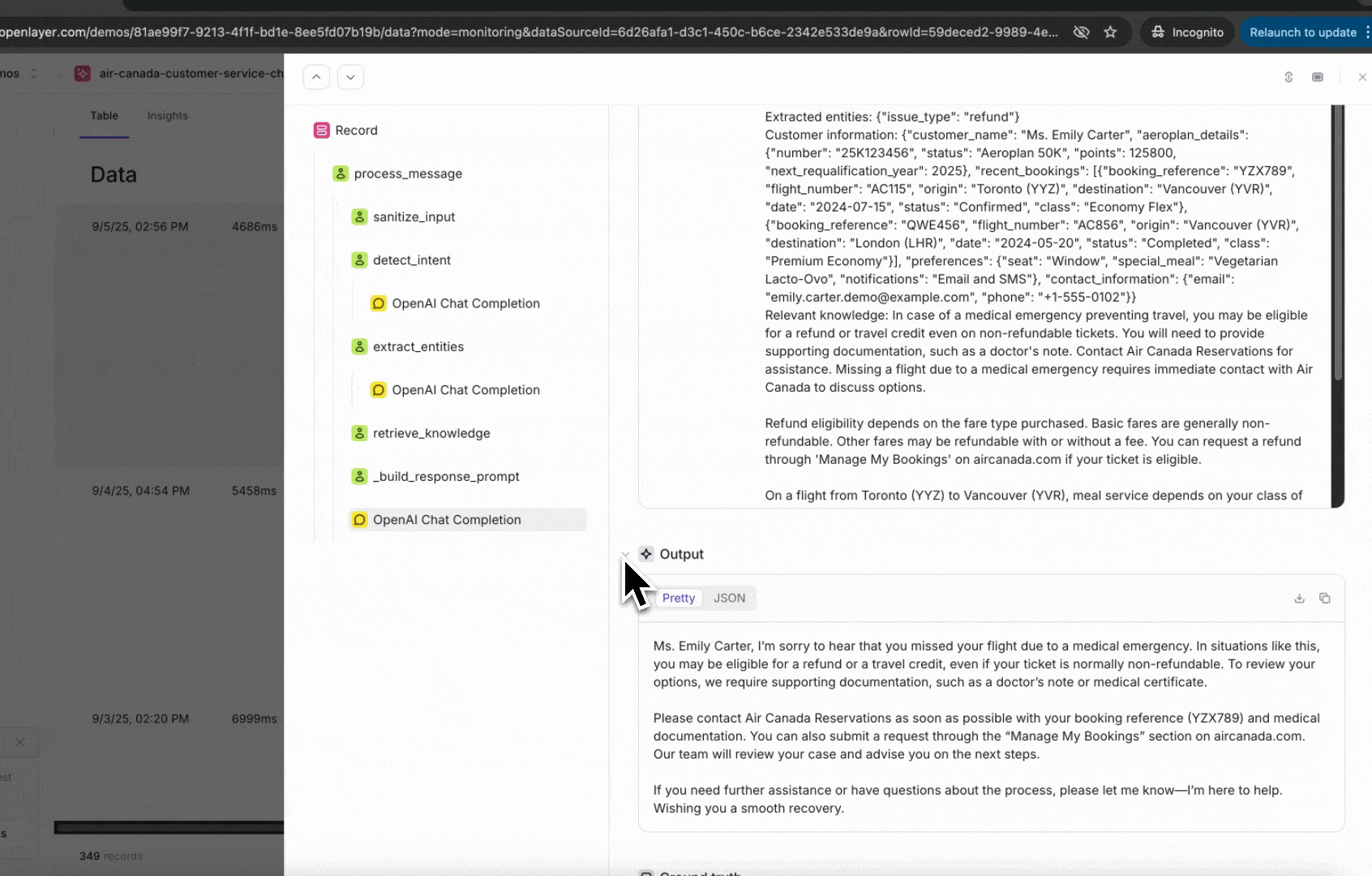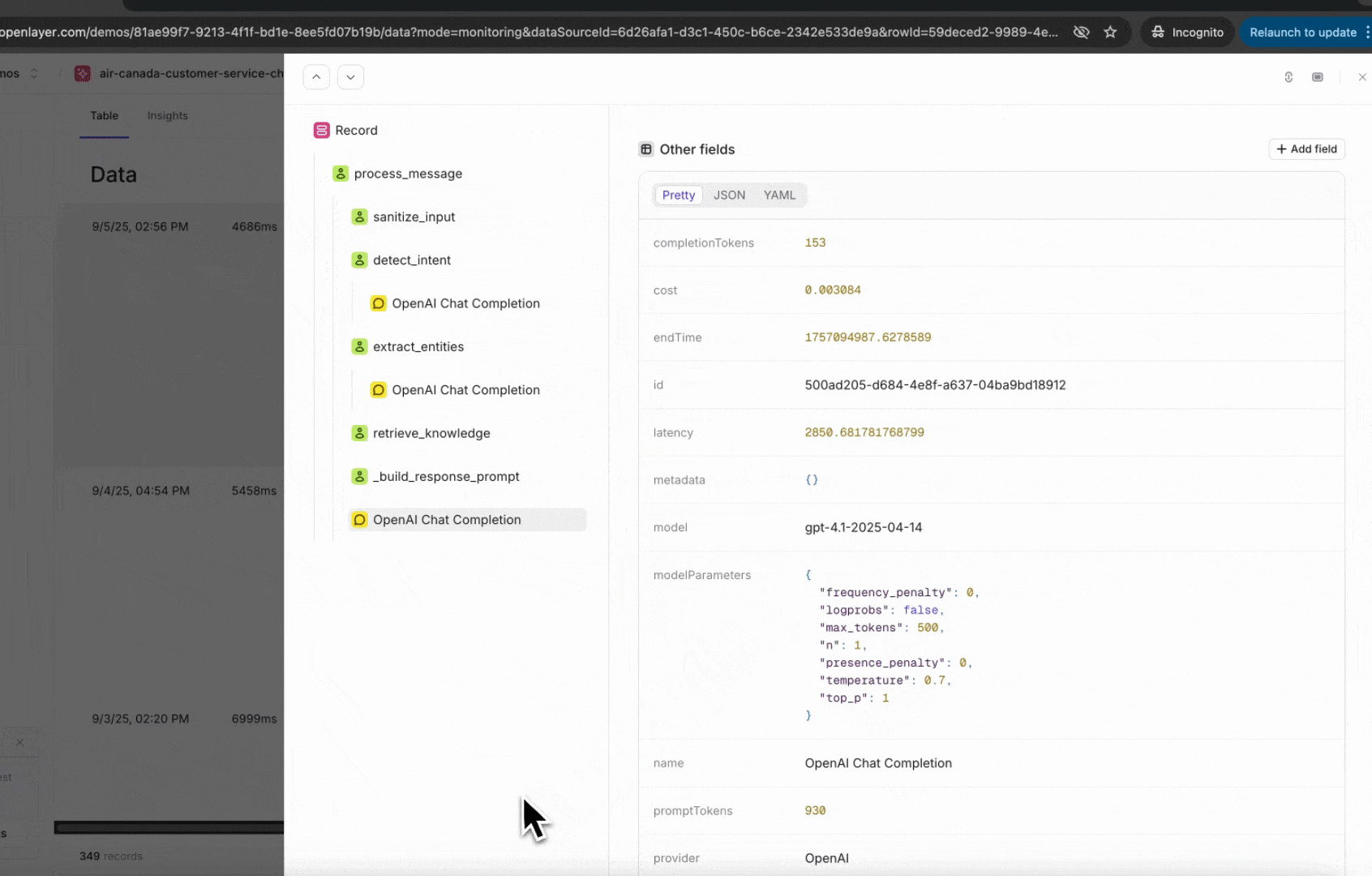
3
Set up tests
You can run automated tests at a regular cadence on top of your traces.
These tests cover a wide range of quality dimensions, from latency and cost to hallucination and prompt injection tests.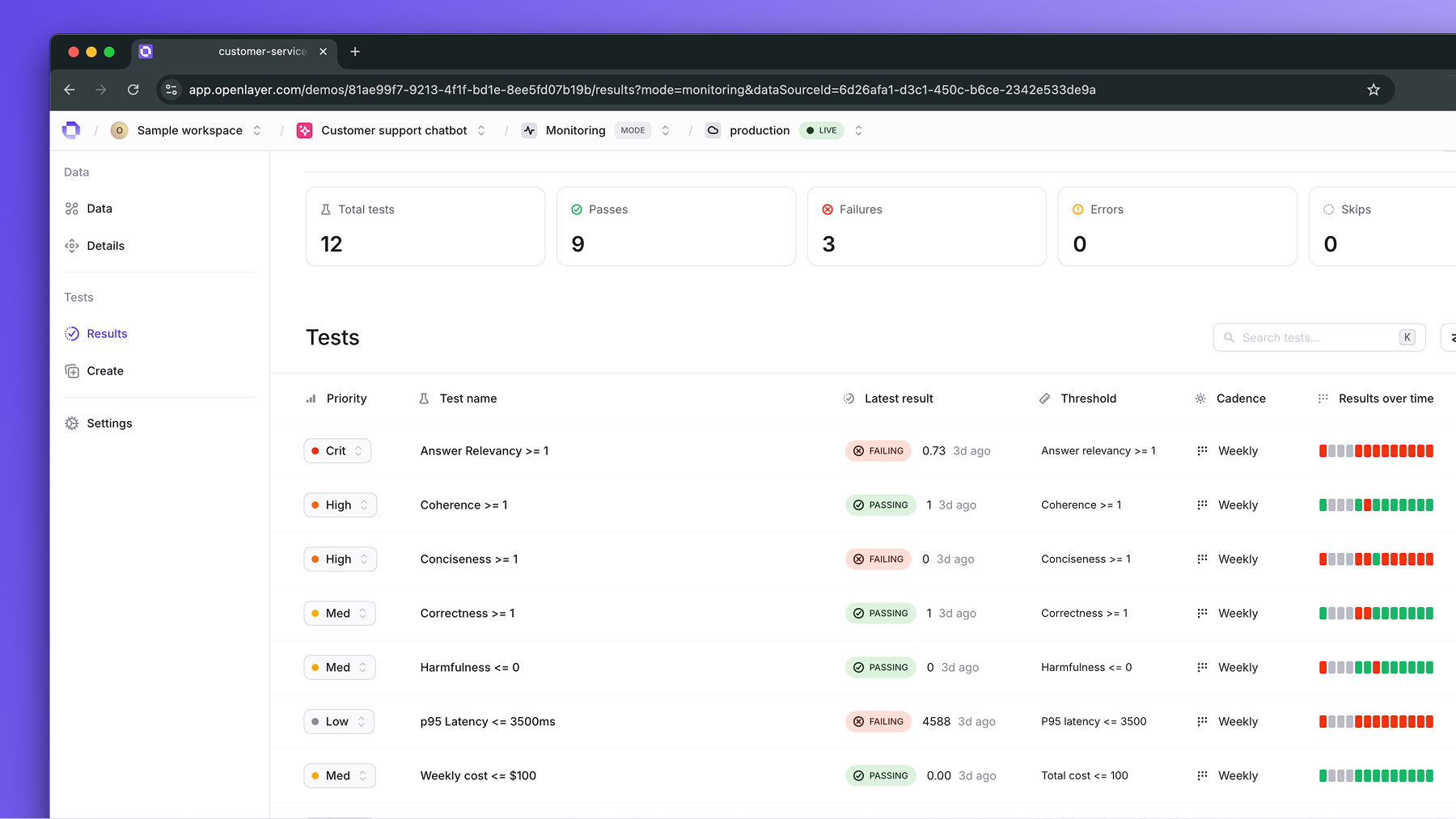
4
Get notified and act
Over time, successive test results show how your system’s health is evolving.
Configure notifications to be alerted immediately when a test fails—so you can
respond before small issues snowball into production incidents.
Next steps
By continuously tracing, testing, and alerting, Openlayer gives you a feedback system that keeps your AI trustworthy in real-world conditions. To try it out, check out the Instrument your code guide to learn how to integrate.FAQ
Does trace data always have to be sent to Openlayer?
Does trace data always have to be sent to Openlayer?
No, there are a few alternatives.First, the Openlayer platform can be deployed on-premises. In this case, all the
data remains private in your own infrastructure.Second, if you are already logging the data to a table in a data lake, such as
BigQuery, Databricks, Snowflake, and others, you can use a connector, and, Openlayer
will read the data from the table and run tests without replicating it.If you prefer to use the SaaS version of Openlayer,
Openlayer takes security seriously and is SOC 2 Type II compliant.
What's the difference between monitoring mode and development mode?
What's the difference between monitoring mode and development mode?
The main difference between monitoring and development mode is the data used to run tests.In development mode, tests run on a validation dataset curated by you. Furthermore, these
tests tend to run as part of a CI/CD pipeline to ensure that you are making systematic progress
as you iterate on your system versions.In monitoring mode, tests run continuously on top of your live data, so you can spot issues
as soon as they appear in production.
What's the difference between monitoring mode and guardrails?
What's the difference between monitoring mode and guardrails?
Guardrails complement tests in monitoring mode.
While your Openlayer tests run continuously on top of your live data and trigger a
notification in case of failure, guardrails validate inputs and outputs in real time
and block or modify them if they don’t meet your constraints.Together, they give you both proactive coverage (through tests) and reactive protection (through guardrails).See the Guardrails overview for details.