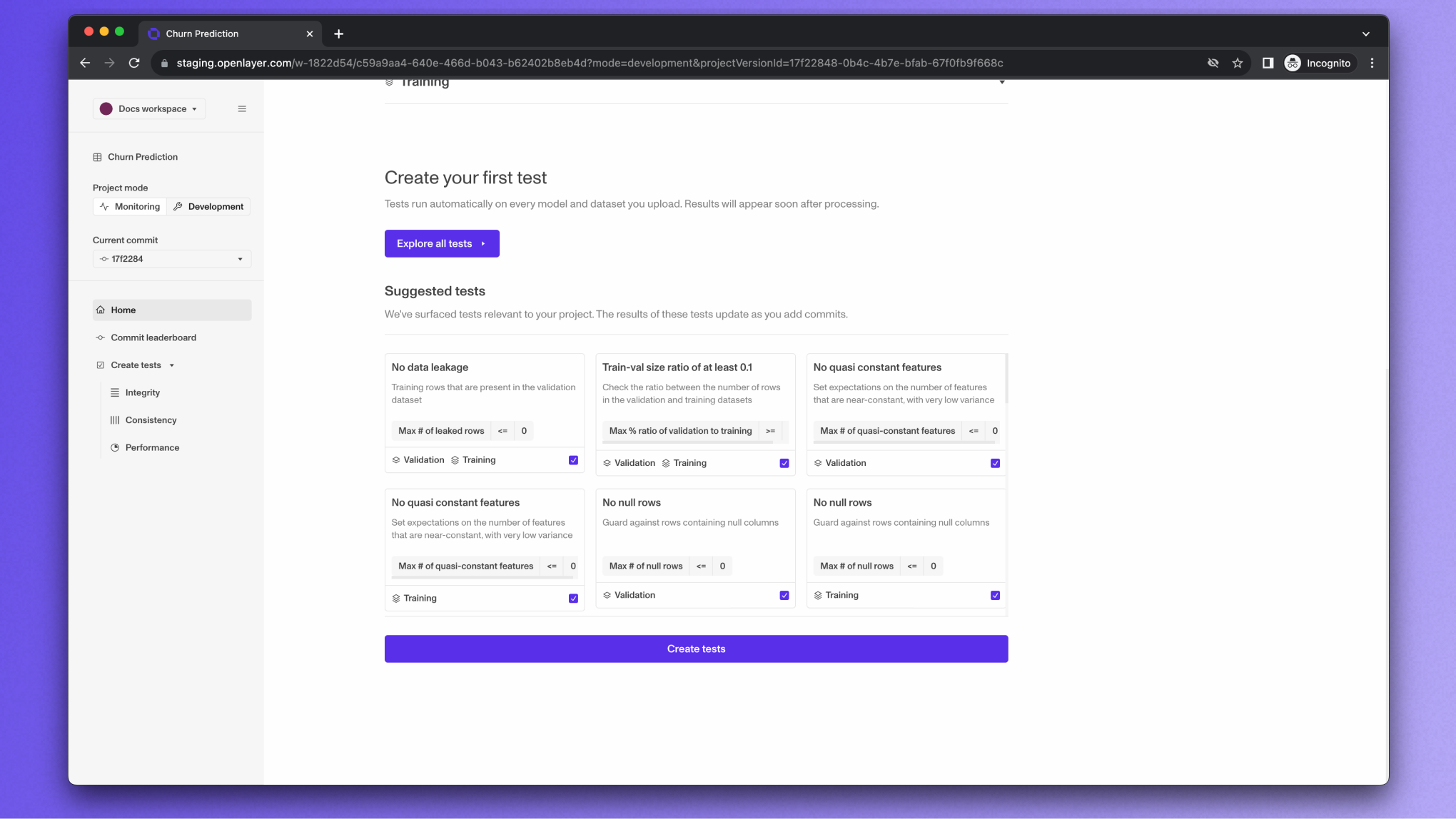
Introduction to tests
Practitioners must have high expectations for their models and data to build trustworthy AI/ML. Openlayer tests materialize these expectations. If we used plain English to describe them, some test examples would be:- Expect less than 3% of values missing for a feature from the training set.
- Ensure that there is no leakage between training and validation sets.
- Assert that the model has an average semantic similarity of more than 0.9 for critical queries.
- Make sure that the model is robust to typos and paraphrases.
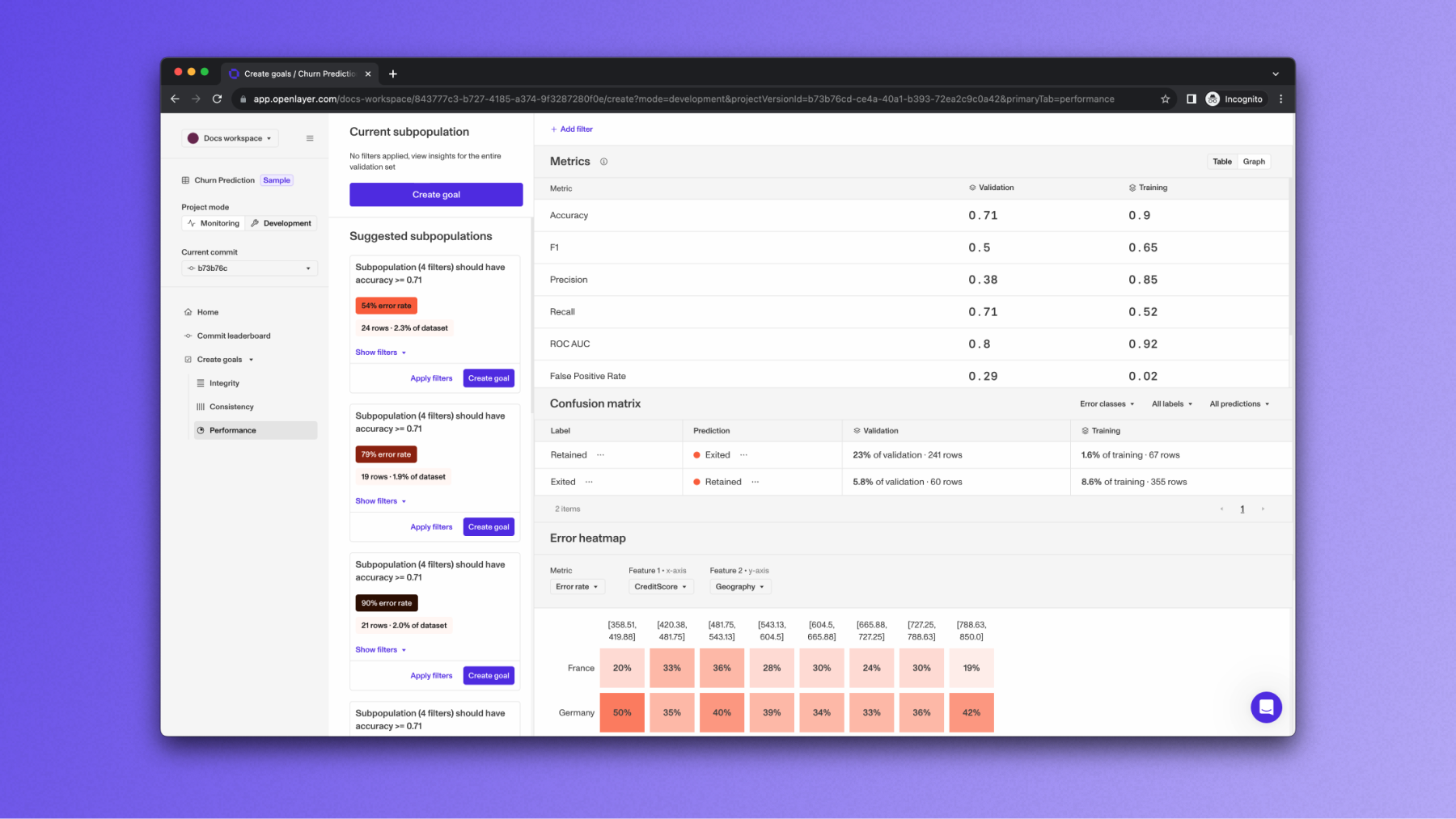
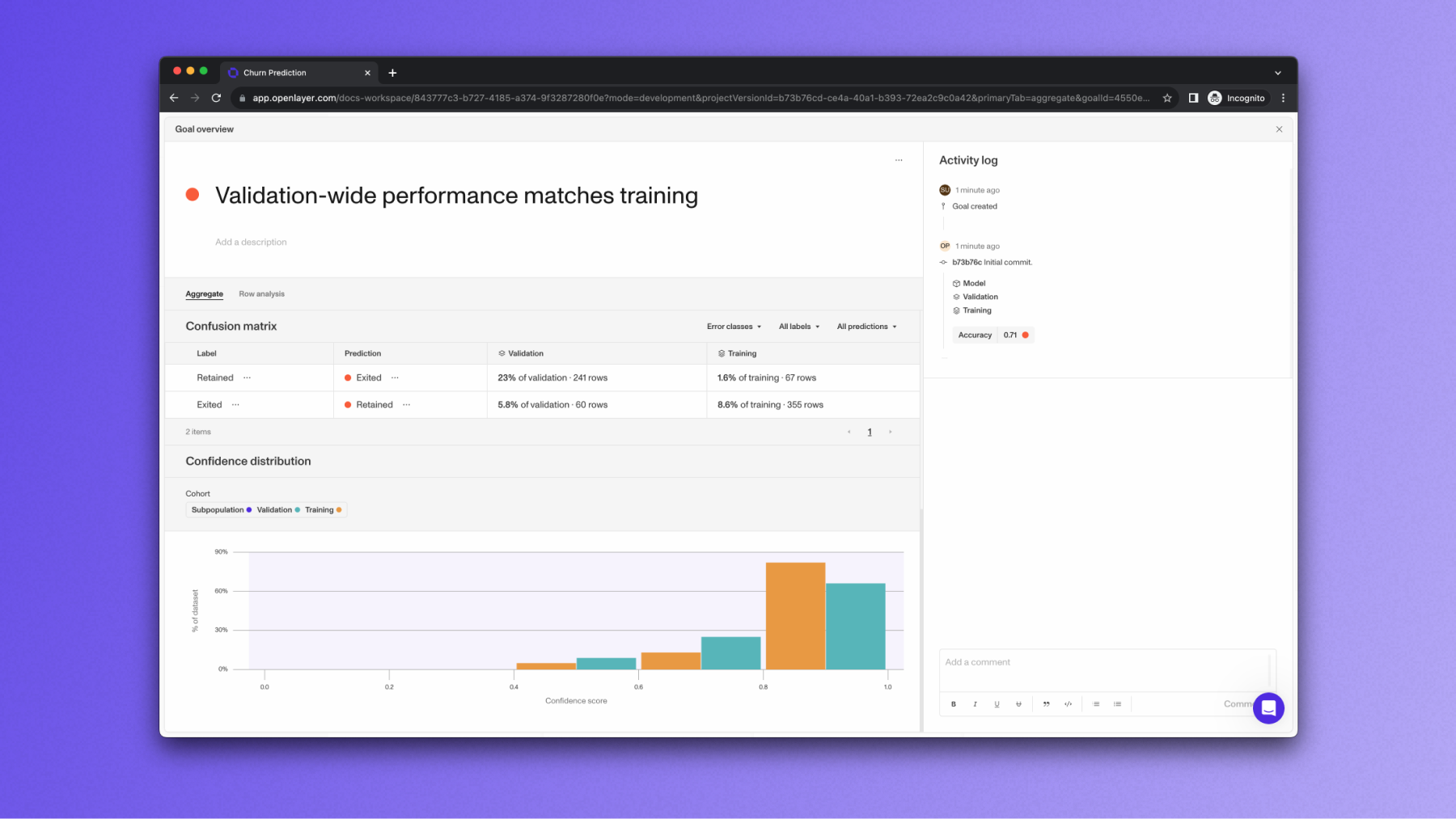
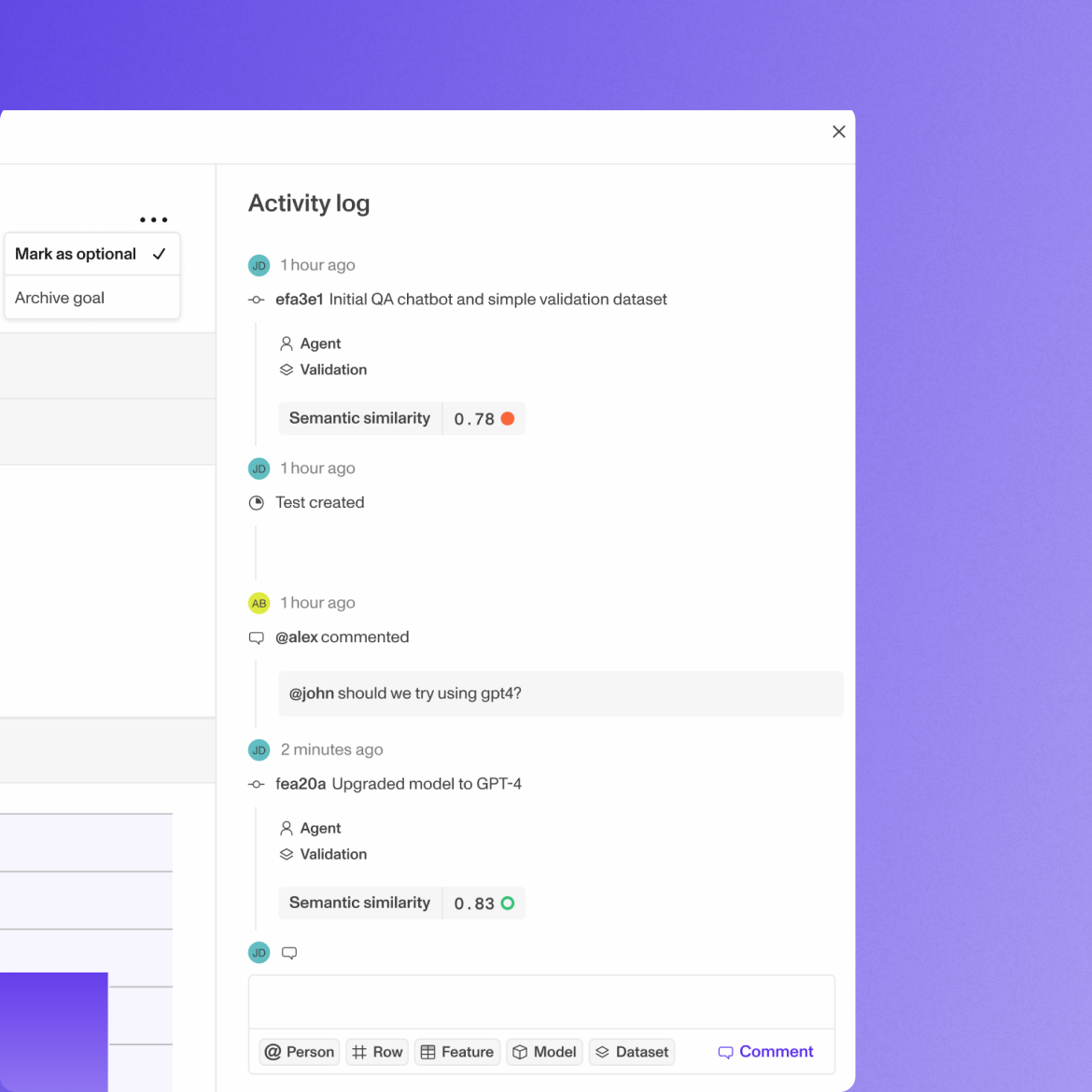
Test types
If we take a closer look at the test examples presented in the previous section, it is possible to note that some tests rely on a single dataset, while others use two datasets, and some even need the model as well. This motivates the existence of different test types. Each test type is designed to cover a distinct aspect of quality and performance. Let’s double-click on this idea.Definitions
On Openlayer, tests are organized into five categories: integrity, consistency, performance, fairness, and robustness.Integrity
Integrity tests are defined based on quantities computed from individual datasets. Usually, they are related to data quality. For example, the number of missing values on a dataset is a typical integrity test.Consistency
Consistency tests are associated with the relationship between two datasets, namely the training and validation sets. Ultimately, the training and validation sets should be consistent. Otherwise, there is no point in training the model in a dataset that looks nothing like the one used to validate it. Consistency tests help ensure that these datasets are sufficiently aligned while keeping the separation needed. An example of a consistency test is the test that asserts there is no leakage between training and validation sets.Performance
Performance tests set guardrails on the model’s performance on the whole validation set or specific subpopulations. They usually rely on aggregate metrics (which vary according to the task type — refer to the Aggregate metrics guide for details). For instance, the test that sets an accuracy threshold for a specific subpopulation within the validation set is a performance test.Fairness
Fairness tests assess the model using different fairness metrics. The fairness metrics also change depending on the task type. Some examples are equal opportunity and demographic parity metrics for tabular models; and invariance to gender pronoun usage for language models.Robustness
Robustness tests are all about asserting robustness to different data perturbation recipes. The idea is that it is better to try to anticipate the edge cases that a model will invariably encounter in production. By doing so, corrective action can be taken before deployment. For example, asserting that a language model is robust to typos, and paraphrases; or that tabular models are invariant to certain feature value changes.Most categories above are valid for all the task types supported by Openlayer: from tabular regression to LLMs. However, the tests within the categories for each task type differ. Each task type has its idiosyncrasies, and the tests are customized to address prevalent challenges specific to it. For example, for LLMs, an important issue is ensuring that the model output follows a specific format (JSON, for example). This fits under the umbrella of integrity tests because it uses a single dataset. On the other hand, such a test doesn’t apply to tabular classification or tabular regression, and is, thus, replaced with specific tests such as correlated features, feature value ranges, etc.
Test hierarchy
The different test types cover complementary aspects of quality and performance. Additionally, they form a hierarchy. Our recommended approach involves beginning by creating and tackling the easily achievable integrity tests before moving on to consistency and the successive types, up to robustness. The reason for the suggested order is that some tests are tightly interrelated. For example, a high number of missing values on the training set (an integrity test) may be the culprit for a model bias (fairness test). Solving the issue at its root can produce positive ripple effects downstream.Test creation process
At this point, we have explored what Openlayer tests are and how they are organized. Furthermore, we know that at their core, tests define expectations on the model and data. A natural question that arises next is: where do these expectations come from for a concrete project? In other words, how does one create the tests for their models and datasets? In practice, tests can have many origin stories. For example, a performance test could have been created even before model development started, since a team could already have envisioned the target performance they wanted to achieve. Alternatively, a consistency test can be created well into model development, after the team noticed that the culprit for a poor performance was the data drift between training and validation sets. Even though each AI/ML project is unique, in this guide, we explore some of the common paths for test creation.Openlayer suggestions
When models and datasets are onboarded to Openlayer, a series of analyses are run to find potentially important insights. As a consequence, the Openlayer platform can automatically suggest a series of tests that might be interesting for the use case at hand. These suggested tests can give teams a head start on the development process. Below is a screenshot of the list of suggested tests for a sample text classification project.